第17章 定时任务、批处理

分类: springboot 专栏: springboot3.0新教材 标签: 定时任务 批处理
2024-03-03 22:08:55 1727浏览
定时任务
使用@Schedule 实现定时任务
步骤:
(1)创建 Spring Boot 项目 schedule1,添加 spring-boot-starter-web 依赖。
(2)在启动类上添加@EnableScheduling 注解开启定时任务。
(3)创建定时任务类 ScheduleService,将类中各方法通过@Schedule 注解设置为定时任务。
- fixedRate 适合需要固定时间间隔执行任务的场景,但如果任务执行时间比指定的间隔长,可能会导致任务重叠。(是按开始时间算的,有可能上一个任务还没执行下一个任务就开始了。)
- fixedDelay 适合需要确保上一次任务执行完成后再等待固定时间间隔执行下一次任务的场景,可以避免任务重叠。
cron 表达式后面会详解
@Service
@Slf4j
public class ScheduleService {
@Scheduled(fixedRate = 5000)//上一次开始执行时间点之后5秒再执行
public void scheduled1() {
log.info("******scheduled1使用fixedRate执行定时任务");
}
//第一次延迟1秒后执行,之后按fixedRate的规则每 5 秒执行一次
@Scheduled(initialDelay = 1000,fixedRate = 5000)//
public void scheduled2() {
log.info("******scheduled2使用initialDelay和fixedRate执行定时任务");
}
@Scheduled(fixedDelay = 10000)//上一次执行完毕时间点之后10秒再执行
public void scheduled3() {
log.info("******scheduled3使用fixedDelay执行定时任务");
}
@Scheduled(cron="0/20 * * * * ?") //每隔20秒执行一次,从0秒算起
private void scheduled4(){
log.info("******scheduled4使用cron执行定时任务");
}
}
(4)运行测试
15:18:45.954 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:18:45.954 [ scheduling-1]: ******scheduled3使用fixedDelay执行定时任务
15:18:45.955 [ restartedMain]: Started ScheduleDemoApplication in 2.008 seconds (process running for 2.88)
15:18:46.968 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:18:50.957 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:18:51.959 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:18:55.960 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:18:55.960 [ scheduling-1]: ******scheduled3使用fixedDelay执行定时任务
15:18:56.968 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:00.010 [ scheduling-1]: ******scheduled4使用cron执行定时任务
15:19:00.965 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:01.968 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:05.963 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:05.963 [ scheduling-1]: ******scheduled3使用fixedDelay执行定时任务
15:19:06.955 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:10.962 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:11.968 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:15.958 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:15.973 [ scheduling-1]: ******scheduled3使用fixedDelay执行定时任务
15:19:16.966 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:20.001 [ scheduling-1]: ******scheduled4使用cron执行定时任务
15:19:20.962 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:21.969 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:25.954 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:25.986 [ scheduling-1]: ******scheduled3使用fixedDelay执行定时任务
15:19:26.970 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:30.961 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:31.968 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:35.968 [ scheduling-1]: ******scheduled1使用fixedRate执行定时任务
15:19:35.998 [ scheduling-1]: ******scheduled3使用fixedDelay执行定时任务
15:19:36.960 [ scheduling-1]: ******scheduled2使用initialDelay和fixedRate执行定时任务
15:19:40.005 [ scheduling-1]: ******scheduled4使用cron执行定时任务cron 表达式
@Scheduled(cron="0/20 * * * * ?") //每隔20秒执行一次,从0秒算起
private void scheduled4(){
log.info("******scheduled4使用cron执行定时任务");
}上述案例的最后一个任务,使用的是 cron 表达式,用到设置任务执行的时间规则。
cron表达式是一个字符串其语法为:[秒] [分] [小时] [日] [月] [周] [年],其中[年]为非必填项,因此通常 cron 表达式通常由 6 或 7 部分内容组成,内容的取值为数字或者一些 cron表达式约定的特殊字符,这些特殊字符称为“通配符”,每一个通配符分别代指一种值。
cron表达式各项的取值范围

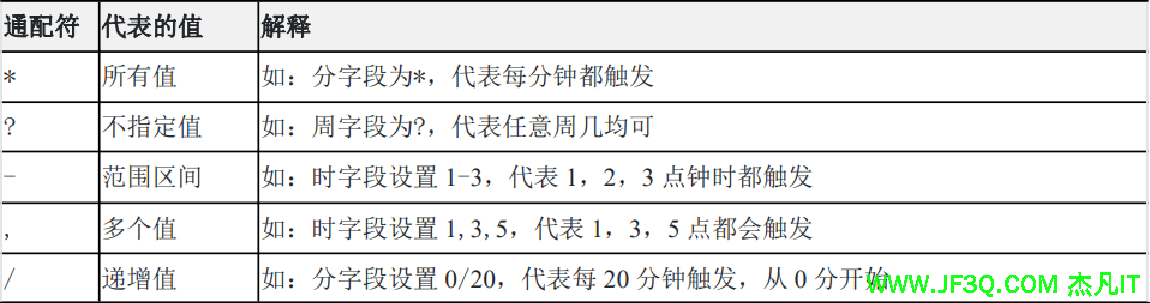
补充:在 Cron 表达式中,"W" 是一个特殊字符,表示最接近指定日期的工作日(Weekday)
示例:
每 5 秒执行一次:0/5 ?
每 5 分钟执行一次:0 0/5 * ?
每个小时的 1 分、15 分、45 分执行一次:0 1,15,45 * ?
每天 23 点 59 分 59 秒执行一次:59 59 23 ?
每月 15 号凌晨 3 点执行一次:0 0 3 15 * ?
每月最后一天 12 点执行一次:0 0 12 L * ?
这些规则不太好记,有个好的办法就是订制自动生成,见网址 https://cron.qqe2.com/ ,在界面中定制即可自动生成 cron 表达式。
多线程处理定时任务
看到控制台输出的结果,所有的定时任务都是通过一个线程来处理的,但当定时任务增多,如果一个任务卡死,会导致其他任务也无法执行。所以任务多的情况下可以考虑使用多线程。需要做的仅仅是实现 SchedulingConfigurer 接口,重写 configureTasks 方法就行了。
@Configuration
//所有的定时任务都放在一个线程池中,定时任务启动时使用不同都线程。
public class ScheduleConfig implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
//设定一个长度10的定时任务线程池
taskRegistrar.setScheduler(Executors.newScheduledThreadPool(10));
}
}运行测试
使用 Quartz 实现定时任务
Spring Boot 集成了 Quartz,可以实现比较复杂的定时任务,同样支持 cron 表达式。基本流程是:
(1)创建做为任务的原始类。(业务代码)job
(2)将原始类封装为 JobDetail。
(3)创建触发器,绑定 JobDetail,并规定时间规则。
(4)开启一个或多个触发器。(调度器)
下面创建实际项目进行实践。
(1)创建项目 quartz1,添加 spring-boot-starter-quartz 依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>(2)创建一个普通类 QuartzJob1,类中方法将作为“任务
@Service
public class QuartzJob1 {
public void doJob(){
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("QuartzJob1----" + sdf.format(new Date()));
}
}(3)创建一个类,继承 QuartzJobBean,类中重写的方法同样作为“任务”注意此处的 jobExecutionContext 参数,在 JobDetail 绑定该 Job 之后,可以传参数过来,通过该参数可以在 Job 中获取传过来的参数
public class QuartzJob2 extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
//获取从绑定当前任务的JobDetail中传递过来的参数
String orderNo=jobExecutionContext.getJobDetail().getJobDataMap().get("orderNo").toString();
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println("QuartzJob2----orderNo:" +orderNo+ sdf.format(new Date()));
}
}
(4)创建配置类 QuartzConfig,分别将上述任务类封装成 JobDetail,并分别创建触发器,最后触发这两个触发器。
@Configuration
public class QuartzConfig {
@Bean
//将普通类QuartzJob1封装成一个JobDetail
MethodInvokingJobDetailFactoryBean jobDetail1(){
MethodInvokingJobDetailFactoryBean jobDetail=new MethodInvokingJobDetailFactoryBean();
jobDetail.setTargetBeanName("quartzJob1");//指定实例
jobDetail.setTargetMethod("doJob");//指定方法
return jobDetail;
}
@Bean //将继承QuartzJobBean类的QuartzJob2封装成一个JobDetail
JobDetailFactoryBean jobDetail2(){
JobDetailFactoryBean jobDetail=new JobDetailFactoryBean();
jobDetail.setJobClass(QuartzJob2.class); //指定要封装的类
JobDataMap map=new JobDataMap();
map.put("orderNo","1001"); //传递参数
jobDetail.setJobDataMap(map);
jobDetail.setDurability(true);//用于设置 Job 的持久性。 就像是给这个任务打上了一个标签,告诉调度器要对这个任务进行特殊处理,确保它不会因为没有触发器而被移除。
return jobDetail;
}
@Bean //为任务jobDetail1创建触发规则
SimpleTriggerFactoryBean trigger1(){
SimpleTriggerFactoryBean trigger=new SimpleTriggerFactoryBean();
trigger.setJobDetail(jobDetail1().getObject());
trigger.setRepeatCount(5);//重复5次
trigger.setStartDelay(2000);//第一次延迟2秒才执行
trigger.setRepeatInterval(5000);//每次间隔5秒执行
return trigger;
}
@Bean //为任务jobDetail2创建触发规则,可使用CRON规则
CronTriggerFactoryBean trigger2(){
CronTriggerFactoryBean trigger=new CronTriggerFactoryBean();
trigger.setJobDetail(jobDetail2().getObject());
trigger.setCronExpression("0/20 * * * * ?");//每分钟的第0,20,40秒执行一次
return trigger;
}
@Bean //启动上面创建的两个触发器
SchedulerFactoryBean schedulerFactoryBean(){
SchedulerFactoryBean mySchedule=new SchedulerFactoryBean();
SimpleTrigger trigger_1=trigger1().getObject();
CronTrigger trigger_2=trigger2().getObject();
mySchedule.setTriggers(trigger_1,trigger_2);//计划同时装配多个触发器
return mySchedule;
}
}(5)运行测试
QuartzJob1----2024-03-03 18:37:12
QuartzJob1----2024-03-03 18:37:17
QuartzJob2----orderNo:10012024-03-03 18:37:20
QuartzJob1----2024-03-03 18:37:22
QuartzJob1----2024-03-03 18:37:27
QuartzJob1----2024-03-03 18:37:32
QuartzJob1----2024-03-03 18:37:37
QuartzJob2----orderNo:10012024-03-03 18:37:40
QuartzJob2----orderNo:10012024-03-03 18:38:00
QuartzJob2----orderNo:10012024-03-03 18:38:20批处理 Spring Batc
参考文章https://www.null123.com/question/detail-2502614.html
Spring Batch 是一个轻量级的批处理框架,主要用来读取大量数据,然后进行一定处理后输出成指定的形式。Spring Batch 还提供记录/跟踪、事务管理、作业处理统计、作业重启以及资源管理等功能。
Spring Batch 提供了 ItemReader、ItemProcessor 和 ItemWriter 来完成数据的读取、处理以及写出操作,并且可以将批处理的执行状态持久化到数据库中。Spring Batch 主要由以下几部分组成
以上 SpringBatch 的主要组成部分只需注册成 Spring 的 Bean 即可。若想开启批处理的支持还需在配置类上使用@EnableBatchProcessing。
(1)Spring Batch 提供了一些常用的 ItemReader(即数据的读取逻辑),例如:
- JdbcPagingltemReader 用来读取数据库中的数据
- StaxEventltemReader 用来读取 XML 数据
- FlatFileltemReader 用来加载普通文件(本样例使用该 ItemReader)
(2)Spring Batch 提供了一些常用的 ItemWriter(即数据的写出逻辑),例如:
- FlatFileltemWriter 表示将数据写出为一个普通文件。
- StaxEvenltemWriter 表示将数据写出为 XML。
还有针对不同数据库提供的写出操作支持类,如 MongoltemWriter、JpaltemWriter、 Neo4jItemWriter 以及 HibernateltemWriter 等。
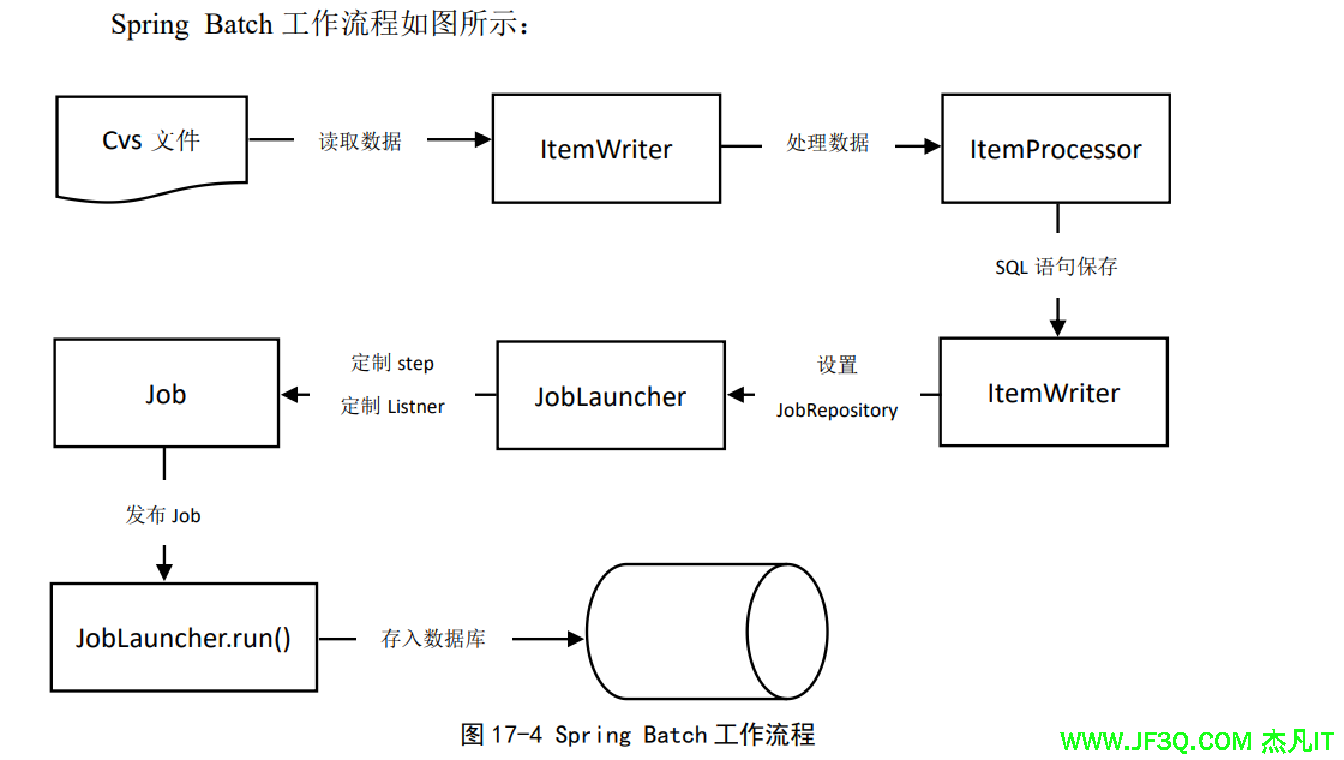
springboot使用批处理实战
需求
假设现在有一个data.csv文件,文件中保存了4条成绩数据,需要通过批处理框架读取文件中的内容,然后插入数据表中。
为了方便演示,本次案例只实现ItemReader(数据的读取)和ItemWriter(数据的写出),中间的ItemProcessor(数据的处理)不实现,即数据读取后不做任何处理,直接入库
id coursename score
1 语文 78
2 数学 91
3 英语 82
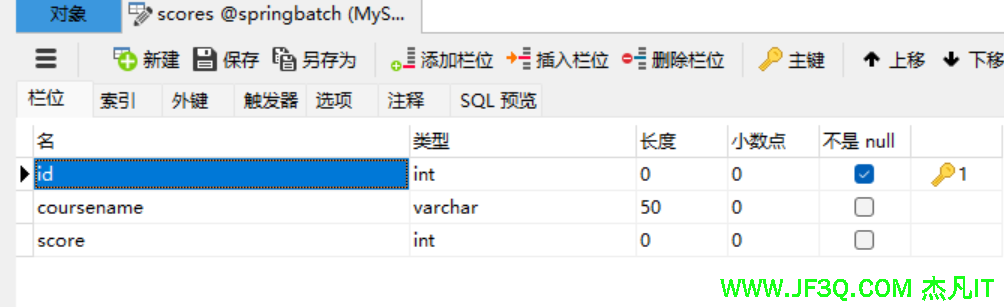
4 物理 80创建数据库和表
/*
Navicat MySQL Data Transfer
Source Server : MySQL8
Source Server Version : 80022
Source Host : localhost:3306
Source Database : springbatch
Target Server Type : MYSQL
Target Server Version : 80022
File Encoding : 65001
Date: 2024-03-03 21:29:54
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for batch_job_execution
-- ----------------------------
DROP TABLE IF EXISTS `batch_job_execution`;
CREATE TABLE `batch_job_execution` (
`JOB_EXECUTION_ID` bigint NOT NULL,
`VERSION` bigint DEFAULT NULL,
`JOB_INSTANCE_ID` bigint NOT NULL,
`CREATE_TIME` datetime(6) NOT NULL,
`START_TIME` datetime(6) DEFAULT NULL,
`END_TIME` datetime(6) DEFAULT NULL,
`STATUS` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`EXIT_CODE` varchar(2500) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`EXIT_MESSAGE` varchar(2500) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`LAST_UPDATED` datetime(6) DEFAULT NULL,
PRIMARY KEY (`JOB_EXECUTION_ID`) USING BTREE,
KEY `JOB_INST_EXEC_FK` (`JOB_INSTANCE_ID`) USING BTREE,
CONSTRAINT `JOB_INST_EXEC_FK` FOREIGN KEY (`JOB_INSTANCE_ID`) REFERENCES `batch_job_instance` (`JOB_INSTANCE_ID`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_job_execution_context
-- ----------------------------
DROP TABLE IF EXISTS `batch_job_execution_context`;
CREATE TABLE `batch_job_execution_context` (
`JOB_EXECUTION_ID` bigint NOT NULL,
`SHORT_CONTEXT` varchar(2500) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`SERIALIZED_CONTEXT` text CHARACTER SET utf8 COLLATE utf8_general_ci,
PRIMARY KEY (`JOB_EXECUTION_ID`) USING BTREE,
CONSTRAINT `JOB_EXEC_CTX_FK` FOREIGN KEY (`JOB_EXECUTION_ID`) REFERENCES `batch_job_execution` (`JOB_EXECUTION_ID`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_job_execution_params
-- ----------------------------
DROP TABLE IF EXISTS `batch_job_execution_params`;
CREATE TABLE `batch_job_execution_params` (
`JOB_EXECUTION_ID` bigint NOT NULL,
`TYPE_CD` varchar(6) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`KEY_NAME` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`STRING_VAL` varchar(250) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`DATE_VAL` datetime(6) DEFAULT NULL,
`LONG_VAL` bigint DEFAULT NULL,
`DOUBLE_VAL` double DEFAULT NULL,
`PARAMETER_TYPE` varchar(6) DEFAULT NULL,
`PARAMETER_NAME` varchar(100) DEFAULT NULL,
`IDENTIFYING` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`PARAMETER_VALUE` varchar(250) DEFAULT NULL,
KEY `JOB_EXEC_PARAMS_FK` (`JOB_EXECUTION_ID`) USING BTREE,
CONSTRAINT `JOB_EXEC_PARAMS_FK` FOREIGN KEY (`JOB_EXECUTION_ID`) REFERENCES `batch_job_execution` (`JOB_EXECUTION_ID`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_job_execution_seq
-- ----------------------------
DROP TABLE IF EXISTS `batch_job_execution_seq`;
CREATE TABLE `batch_job_execution_seq` (
`ID` bigint NOT NULL,
`UNIQUE_KEY` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
UNIQUE KEY `UNIQUE_KEY_UN` (`UNIQUE_KEY`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_job_instance
-- ----------------------------
DROP TABLE IF EXISTS `batch_job_instance`;
CREATE TABLE `batch_job_instance` (
`JOB_INSTANCE_ID` bigint NOT NULL,
`VERSION` bigint DEFAULT NULL,
`JOB_NAME` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`JOB_KEY` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`JOB_INSTANCE_ID`) USING BTREE,
UNIQUE KEY `JOB_INST_UN` (`JOB_NAME`,`JOB_KEY`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_job_seq
-- ----------------------------
DROP TABLE IF EXISTS `batch_job_seq`;
CREATE TABLE `batch_job_seq` (
`ID` bigint NOT NULL,
`UNIQUE_KEY` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
UNIQUE KEY `UNIQUE_KEY_UN` (`UNIQUE_KEY`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_step_execution
-- ----------------------------
DROP TABLE IF EXISTS `batch_step_execution`;
CREATE TABLE `batch_step_execution` (
`STEP_EXECUTION_ID` bigint NOT NULL,
`VERSION` bigint NOT NULL,
`STEP_NAME` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`JOB_EXECUTION_ID` bigint NOT NULL,
`CREATE_TIME` datetime(6) NOT NULL,
`START_TIME` datetime(6) DEFAULT NULL,
`END_TIME` datetime(6) DEFAULT NULL,
`STATUS` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`COMMIT_COUNT` bigint DEFAULT NULL,
`READ_COUNT` bigint DEFAULT NULL,
`FILTER_COUNT` bigint DEFAULT NULL,
`WRITE_COUNT` bigint DEFAULT NULL,
`READ_SKIP_COUNT` bigint DEFAULT NULL,
`WRITE_SKIP_COUNT` bigint DEFAULT NULL,
`PROCESS_SKIP_COUNT` bigint DEFAULT NULL,
`ROLLBACK_COUNT` bigint DEFAULT NULL,
`EXIT_CODE` varchar(2500) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`EXIT_MESSAGE` varchar(2500) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`LAST_UPDATED` datetime(6) DEFAULT NULL,
PRIMARY KEY (`STEP_EXECUTION_ID`) USING BTREE,
KEY `JOB_EXEC_STEP_FK` (`JOB_EXECUTION_ID`) USING BTREE,
CONSTRAINT `JOB_EXEC_STEP_FK` FOREIGN KEY (`JOB_EXECUTION_ID`) REFERENCES `batch_job_execution` (`JOB_EXECUTION_ID`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_step_execution_context
-- ----------------------------
DROP TABLE IF EXISTS `batch_step_execution_context`;
CREATE TABLE `batch_step_execution_context` (
`STEP_EXECUTION_ID` bigint NOT NULL,
`SHORT_CONTEXT` varchar(2500) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`SERIALIZED_CONTEXT` text CHARACTER SET utf8 COLLATE utf8_general_ci,
PRIMARY KEY (`STEP_EXECUTION_ID`) USING BTREE,
CONSTRAINT `STEP_EXEC_CTX_FK` FOREIGN KEY (`STEP_EXECUTION_ID`) REFERENCES `batch_step_execution` (`STEP_EXECUTION_ID`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for batch_step_execution_seq
-- ----------------------------
DROP TABLE IF EXISTS `batch_step_execution_seq`;
CREATE TABLE `batch_step_execution_seq` (
`ID` bigint NOT NULL,
`UNIQUE_KEY` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
UNIQUE KEY `UNIQUE_KEY_UN` (`UNIQUE_KEY`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Table structure for scores
-- ----------------------------
DROP TABLE IF EXISTS `scores`;
CREATE TABLE `scores` (
`id` int NOT NULL,
`coursename` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`score` int DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>配置文件application.properties
#spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.url=jdbc:mysql://localhost:3306/springbatch
spring.datasource.username=root
spring.datasource.password=123456
#spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#spring.sql.init.schema-locations=classpath:/org/springframework/batch/core/schema-mysql.sql
#spring.batch.jdbc.initialize-schema=always
#spring.batch.job.enabled=false开启spring batch
启动类上加注解:@EnableBatchProcessing
创建原始数据文件data.csv
id coursename score
1 语文 78
2 数学 91
3 英语 82
4 物理 80创建实体类
@Data
public class Scores {
private int id;
private String coursename;
private int score;
}创建配置类CsvBatchJobConfig
@Configuration
public class CsvBatchJobConfig {
@Autowired
private JobRepository jobRepository;
@Autowired
private PlatformTransactionManager transactionManager;
// 注入DataSource,用来支持持久化操作,这里持久化方案是Spring-Jdbc
@Autowired
DataSource dataSource;
// 配置一个ItemReader,即数据的读取逻辑
@Bean
@StepScope
FlatFileItemReader<Scores> itemReader() {
// FlatFileItemReader 是一个加载普通文件的 ItemReader
FlatFileItemReader<Scores> reader = new FlatFileItemReader<>();
// 由于data.csv文件第一行是标题,因此通过setLinesToSkip方法设置跳过一行
reader.setLinesToSkip(1);
// setResource方法配置data.csv文件的位置
reader.setResource(new ClassPathResource("data.csv"));
// 通过setLineMapper方法设置每一行的数据信息
reader.setLineMapper(new DefaultLineMapper<Scores>(){{
setLineTokenizer(new DelimitedLineTokenizer(){{
// setNames方法配置了data.csv文件一共有3列,分别是id、coursename、以及score,
setNames("id","coursename","score");
// 配置列与列之间的间隔符(这里是空格)
setDelimiter(" ");
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper(){{
setTargetType(Scores.class);
}});
}});
return reader;
}
@Bean
ItemProcessor<Scores, Scores> processor(){//读取和写出之间加一个处理加工
return new ItemProcessor<Scores, Scores>() {
@Override
public Scores process(Scores item) throws Exception {
item.setScore(item.getScore() + 1); // 将分数加1
return item;
}
};
}
// 配置ItemWriter,即数据的写出逻辑
@Bean
JdbcBatchItemWriter jdbcBatchItemWriter() {
// 使用的JdbcBatchltemWriter则是通过JDBC将数据写出到一个关系型数据库中。
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
// 配置使用的数据源
writer.setDataSource(dataSource);
// 配置数据插入SQL,注意占位符的写法是":属性名"
writer.setSql("insert into scores(id,coursename,score) " +
"values(:id,:coursename,:score)");
// 最后通过BeanPropertyItemSqlParameterSourceProvider实例将实体类的属性和SQL中的占位符一一映射
writer.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider<>());
return writer;
}
@Bean
public Step step1() {
return new StepBuilder("csvStep", jobRepository)
.<Scores, Scores>chunk(200, transactionManager)//方法的参数2,表示每读取到两条数据就执行一次write操作
.reader(itemReader())
.processor(processor())
.writer(jdbcBatchItemWriter())
.build();
}
// 配置一个Job
@Bean
public Job helloJob(JobRepository jobRepository, Step step1){
return new JobBuilder( "csvJob", jobRepository)
.start(step1)
.build();
}
}
创建控制器BatchController
@RestController
public class BatchController {
// JobLauncher 由框架提供
@Autowired
JobLauncher jobLauncher;
// Job 为刚刚配置的
@Autowired
Job job;
@GetMapping("/batch")
public void batch() {
try {
JobParameters jobParameters = new JobParametersBuilder()
.toJobParameters();
// 通过调用 JobLauncher 中的 run 方法启动一个批处理
jobLauncher.run(job, jobParameters);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行测试
通过浏览器访问BatchController的batch接口执行批处理,查看数据库,表scores获取了data.csv中的数据。
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论
您可能感兴趣的博客
 新业务
新业务  springboot学习
springboot学习  ssm框架课
ssm框架课  vue学习
vue学习  【带小白】java基础速成
【带小白】java基础速成 