Linux——内存和DMA

标签: Linux——内存和DMA
2023-06-04 18:23:47 247浏览
目录
本章目标:
在前面的所有例子中,我们使用的都是全局变量或在栈上分配的内存。本章我们将先讨论如何动态分配内存和per-CPU变量。类似于 ARM 这样的体系结构,操作硬件都是通过特殊功能寄存器(SFR)来进行的,它们和内存统一编址在 Linux 内核中叫作I/O内存,本章接下来将会讨论与 IO内存相关的内容。本章在最后将会讨论 DMA 的工作原理、映射机制和DMA的统一编程接口,并用一个实例来演示 DMA 的使用。
一、内存组织
从管理内存的方法来区分,可以把计算机分为两种类型,一种是 UMA(一致内存访问。umiform memory access)计数机,另一种 NUMA (非一致内存访向,non-uniform memory access)计机,图7.1 展示了这两种计算机系统。
对于UMA 而言,每一个CPU 访问的都是同一块内存,各 CPU 对内存的访问不存在性能差异。对于NUMA 而言,各内存和各 CPU 都通过总线连接在一起,每个 CPU 都有一个本地内存,访问速度较快,CPU 也可以访问其他 CPU 的本地内存,但速度稍慢。
Linux 为了统一这两种平台,在内存组织中,将最高层次定义为内存节点。图 7.1中的UMA 系统就可以定义一个内存节点,而NUMA 系统就可以定义两个内存节点,很显然,UMA是NUMA的一种特例,所以内核可以将内存都看作 NUMA 的,对应的UMA系统可以被看成只有一个内存节点的 NUMA 系统。之所以要这样来管理,是出于内存分配来考虑的,当要分配一块内存时,应该先考虑从 CPU 的本地内存对应的节点来分配内存,如果不能满足要求,再考虑从非本地内存的节点上分配内存。
Linux 内存管理的第二个层次为区,每个内存节点都划分为多个区,目前内核中定义了以下几个区。
ZONE_DMA:适合于DMA 操作的内存区。例如在x86 系统上,ISA 总线因为地址总线宽度的原因,只能访问最低的 16MB 区域的内存,那么在该系统上,DMA 内存区就被限制在这低16MB 内存区内。但对于像ARM这样的SOC 系统,DMA 内存区通常是没有限制的。
ZONE_DMA32:在64位的系统上使用32位地址寻址的适合 DMA 操作的内存区例如在AMD64系统上,该区域为低4GB 的空间。在32位系统上,本区域通常是空的。
ZONE_NORMAL:常规内存区域,指的是可以直接映射到内核空间的内存。所谓直接映射是指物理地址和映射后的虚拟地址之间存在着一种简单的关系,那就是物理地址加上一个固定的偏移就可以得到映射之后的虚拟内存地址。在 32 位系统上,如果用户空间和内核空间的划分是以3GB 为界限那么这个偏移就是(0xC000000- 物理内存起始地址)。以3GB 为界限的 32 位系统,内核空间只有 1GB,除去用于特殊目的的一段内核内存空间(通常是高128MB 内存空间),常规内存区域通常指的就是低于896MB 的这部第分物理内存。常规内存区域是内核空间中最频繁使用的一段内存空间,在32 位系统上,指的就是除去 ZONE_DMA而低于896MB 的这段物理内存。
ZONE_HIGHMEM:高端内存。在32位系统上,通常指的是高于896MB 的物理内存:而在 64 位系统上,因为内核空间可以很大,所以一般没有高端内存。要将这段物理内存映射在内核空间的话,需要通过单独的映射来完成,而这种映射通常不能保证物理地址和虚拟地址之间的固定对应关系《如常规内存的固定偏移)。
ZONE_MOVABLE:一个伪内存区域,在防止物理内存碎片时会用到该区域。
将内存按区域划分,主要是为了满足特定的要求。比如要分配一段用于 DMA 操作的内存,那么就只能从 ZONE_DMA 区域中分配,要进行常规操作的内存通常就从ZONE_NORMAL区域中划分。但是如果ZONE_NORMAL区域的内存不足时,内核会尝试从ZONE_DMA 区域中分配。
Linux 内存管理的第三个层次为页,对物理内存而言,通常叫作页帧或页框(本书在不做特定区分时都简称为“页”)。页的大小由 CPU 的内存管理单元 MMU来决定,而通常MMU又支持了不同的页大小(例如在 ARM 体系结构中,MMU 支持的页大小通常有4KB和1MB)。目前最常见的页大小为4KB。Linux 用 struct page 来表示一个物理页,关于该结构的各成员我们并不关心,但是在进行页分配时需要用到该结构。通过上面的描述,我们对 Linux 内核的内存层次结构有了大致了解,简言之就是内存首先划分成若干个大的节点,每个节点又包含若干个区,而每个区又包含若干页。Linux内核是按页来管理内存的,最基本的内存分配和释放都是按页进行的,接下来就介绍内存页的分配和释放。
二、按页分配内存
首先要介绍的一类页分配函数或宏如下。
struct page *alloc_pages (gfp_t gfp_mask, unsigned int order);
alloc_page(gfp_mask)
void __free_pages(struct page *page, unsigned int order)
alloc_pages 分配2的order 次方连续的物理页,返回值为起始页的struct page 对象地址。因为 Linux 是按伙伴系统来管理物理内存的,所以分配的页数为2的order 次方。很显然,alloc_page 就是用于分配单独的一页物理内存,也就是order为0的alloc_pages函数的封装。 free_pages 用于释放这些分配得到的页,page 为分配时得到的起始页的 struct page 对象地址,order 为分配时指定的order 值。
参数 gfp_mask 稍微比较复杂,它是用于控制页面分配行为的一个掩码值,内核中定义了很多 __GPF_xxx 的掩码,但这些掩码非常底层,使用得并不多。为了使用方便,内核还定义了一组 GFP xxx 的掩码,它本质上是__GPF_xxx 的一些组合,使用也比较多下面重点介绍这一组中最常见的一些掩码。
#ifndef __LINUX_GFP_H
#define __LINUX_GFP_H
#include <linux/mmdebug.h>
#include <linux/mmzone.h>
#include <linux/stddef.h>
#include <linux/linkage.h>
#include <linux/topology.h>
#include <linux/mmdebug.h>
struct vm_area_struct;
/* Plain integer GFP bitmasks. Do not use this directly. */
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
#define ___GFP_WAIT 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_COLD 0x100u
#define ___GFP_NOWARN 0x200u
#define ___GFP_REPEAT 0x400u
#define ___GFP_NOFAIL 0x800u
#define ___GFP_NORETRY 0x1000u
#define ___GFP_MEMALLOC 0x2000u
#define ___GFP_COMP 0x4000u
#define ___GFP_ZERO 0x8000u
#define ___GFP_NOMEMALLOC 0x10000u
#define ___GFP_HARDWALL 0x20000u
#define ___GFP_THISNODE 0x40000u
#define ___GFP_RECLAIMABLE 0x80000u
#define ___GFP_KMEMCG 0x100000u
#define ___GFP_NOTRACK 0x200000u
#define ___GFP_NO_KSWAPD 0x400000u
#define ___GFP_OTHER_NODE 0x800000u
#define ___GFP_WRITE 0x1000000u
/* If the above are modified, __GFP_BITS_SHIFT may need updating */
/*
* GFP bitmasks..
*
* Zone modifiers (see linux/mmzone.h - low three bits)
*
* Do not put any conditional on these. If necessary modify the definitions
* without the underscores and use them consistently. The definitions here may
* be used in bit comparisons.
*/
#define __GFP_DMA ((__force gfp_t)___GFP_DMA)
#define __GFP_HIGHMEM ((__force gfp_t)___GFP_HIGHMEM)
#define __GFP_DMA32 ((__force gfp_t)___GFP_DMA32)
#define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* Page is movable */
#define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)
/*
* Action modifiers - doesn't change the zoning
*
* __GFP_REPEAT: Try hard to allocate the memory, but the allocation attempt
* _might_ fail. This depends upon the particular VM implementation.
*
* __GFP_NOFAIL: The VM implementation _must_ retry infinitely: the caller
* cannot handle allocation failures. This modifier is deprecated and no new
* users should be added.
*
* __GFP_NORETRY: The VM implementation must not retry indefinitely.
*
* __GFP_MOVABLE: Flag that this page will be movable by the page migration
* mechanism or reclaimed
*/
#define __GFP_WAIT ((__force gfp_t)___GFP_WAIT) /* Can wait and reschedule? */
#define __GFP_HIGH ((__force gfp_t)___GFP_HIGH) /* Should access emergency pools? */
#define __GFP_IO ((__force gfp_t)___GFP_IO) /* Can start physical IO? */
#define __GFP_FS ((__force gfp_t)___GFP_FS) /* Can call down to low-level FS? */
#define __GFP_COLD ((__force gfp_t)___GFP_COLD) /* Cache-cold page required */
#define __GFP_NOWARN ((__force gfp_t)___GFP_NOWARN) /* Suppress page allocation failure warning */
#define __GFP_REPEAT ((__force gfp_t)___GFP_REPEAT) /* See above */
#define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL) /* See above */
#define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY) /* See above */
#define __GFP_MEMALLOC ((__force gfp_t)___GFP_MEMALLOC)/* Allow access to emergency reserves */
#define __GFP_COMP ((__force gfp_t)___GFP_COMP) /* Add compound page metadata */
#define __GFP_ZERO ((__force gfp_t)___GFP_ZERO) /* Return zeroed page on success */
#define __GFP_NOMEMALLOC ((__force gfp_t)___GFP_NOMEMALLOC) /* Don't use emergency reserves.
* This takes precedence over the
* __GFP_MEMALLOC flag if both are
* set
*/
#define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL) /* Enforce hardwall cpuset memory allocs */
#define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)/* No fallback, no policies */
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE) /* Page is reclaimable */
#define __GFP_NOTRACK ((__force gfp_t)___GFP_NOTRACK) /* Don't track with kmemcheck */
#define __GFP_NO_KSWAPD ((__force gfp_t)___GFP_NO_KSWAPD)
#define __GFP_OTHER_NODE ((__force gfp_t)___GFP_OTHER_NODE) /* On behalf of other node */
#define __GFP_KMEMCG ((__force gfp_t)___GFP_KMEMCG) /* Allocation comes from a memcg-accounted resource */
#define __GFP_WRITE ((__force gfp_t)___GFP_WRITE) /* Allocator intends to dirty page */
/*
* This may seem redundant, but it's a way of annotating false positives vs.
* allocations that simply cannot be supported (e.g. page tables).
*/
#define __GFP_NOTRACK_FALSE_POSITIVE (__GFP_NOTRACK)
#define __GFP_BITS_SHIFT 25 /* Room for N __GFP_FOO bits */
#define __GFP_BITS_MASK ((__force gfp_t)((1 << __GFP_BITS_SHIFT) - 1))
/* This equals 0, but use constants in case they ever change */
#define GFP_NOWAIT (GFP_ATOMIC & ~__GFP_HIGH)
/* GFP_ATOMIC means both !wait (__GFP_WAIT not set) and use emergency pool */
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_NOIO (__GFP_WAIT)
#define GFP_NOFS (__GFP_WAIT | __GFP_IO)
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_TEMPORARY (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_RECLAIMABLE)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | \
__GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_HARDWALL | __GFP_HIGHMEM | \
__GFP_MOVABLE)
#define GFP_IOFS (__GFP_IO | __GFP_FS)
#define GFP_TRANSHUGE (GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NORETRY | __GFP_NOWARN | \
__GFP_NO_KSWAPD)
/*
* GFP_THISNODE does not perform any reclaim, you most likely want to
* use __GFP_THISNODE to allocate from a given node without fallback!
*/
#ifdef CONFIG_NUMA
#define GFP_THISNODE (__GFP_THISNODE | __GFP_NOWARN | __GFP_NORETRY)
#else
#define GFP_THISNODE ((__force gfp_t)0)
#endif
/* This mask makes up all the page movable related flags */
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE|__GFP_MOVABLE)
/* Control page allocator reclaim behavior */
#define GFP_RECLAIM_MASK (__GFP_WAIT|__GFP_HIGH|__GFP_IO|__GFP_FS|\
__GFP_NOWARN|__GFP_REPEAT|__GFP_NOFAIL|\
__GFP_NORETRY|__GFP_MEMALLOC|__GFP_NOMEMALLOC)
/* Control slab gfp mask during early boot */
#define GFP_BOOT_MASK (__GFP_BITS_MASK & ~(__GFP_WAIT|__GFP_IO|__GFP_FS))
/* Control allocation constraints */
#define GFP_CONSTRAINT_MASK (__GFP_HARDWALL|__GFP_THISNODE)
/* Do not use these with a slab allocator */
#define GFP_SLAB_BUG_MASK (__GFP_DMA32|__GFP_HIGHMEM|~__GFP_BITS_MASK)
/* Flag - indicates that the buffer will be suitable for DMA. Ignored on some
platforms, used as appropriate on others */
#define GFP_DMA __GFP_DMA
/* 4GB DMA on some platforms */
#define GFP_DMA32 __GFP_DMA32
/* Convert GFP flags to their corresponding migrate type */
static inline int allocflags_to_migratetype(gfp_t gfp_flags)
{
WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (((gfp_flags & __GFP_MOVABLE) != 0) << 1) |
((gfp_flags & __GFP_RECLAIMABLE) != 0);
}
#ifdef CONFIG_HIGHMEM
#define OPT_ZONE_HIGHMEM ZONE_HIGHMEM
#else
#define OPT_ZONE_HIGHMEM ZONE_NORMAL
#endif
#ifdef CONFIG_ZONE_DMA
#define OPT_ZONE_DMA ZONE_DMA
#else
#define OPT_ZONE_DMA ZONE_NORMAL
#endif
#ifdef CONFIG_ZONE_DMA32
#define OPT_ZONE_DMA32 ZONE_DMA32
#else
#define OPT_ZONE_DMA32 ZONE_NORMAL
#endif
/*
* GFP_ZONE_TABLE is a word size bitstring that is used for looking up the
* zone to use given the lowest 4 bits of gfp_t. Entries are ZONE_SHIFT long
* and there are 16 of them to cover all possible combinations of
* __GFP_DMA, __GFP_DMA32, __GFP_MOVABLE and __GFP_HIGHMEM.
*
* The zone fallback order is MOVABLE=>HIGHMEM=>NORMAL=>DMA32=>DMA.
* But GFP_MOVABLE is not only a zone specifier but also an allocation
* policy. Therefore __GFP_MOVABLE plus another zone selector is valid.
* Only 1 bit of the lowest 3 bits (DMA,DMA32,HIGHMEM) can be set to "1".
*
* bit result
* =================
* 0x0 => NORMAL
* 0x1 => DMA or NORMAL
* 0x2 => HIGHMEM or NORMAL
* 0x3 => BAD (DMA+HIGHMEM)
* 0x4 => DMA32 or DMA or NORMAL
* 0x5 => BAD (DMA+DMA32)
* 0x6 => BAD (HIGHMEM+DMA32)
* 0x7 => BAD (HIGHMEM+DMA32+DMA)
* 0x8 => NORMAL (MOVABLE+0)
* 0x9 => DMA or NORMAL (MOVABLE+DMA)
* 0xa => MOVABLE (Movable is valid only if HIGHMEM is set too)
* 0xb => BAD (MOVABLE+HIGHMEM+DMA)
* 0xc => DMA32 (MOVABLE+DMA32)
* 0xd => BAD (MOVABLE+DMA32+DMA)
* 0xe => BAD (MOVABLE+DMA32+HIGHMEM)
* 0xf => BAD (MOVABLE+DMA32+HIGHMEM+DMA)
*
* ZONES_SHIFT must be <= 2 on 32 bit platforms.
*/
#if 16 * ZONES_SHIFT > BITS_PER_LONG
#error ZONES_SHIFT too large to create GFP_ZONE_TABLE integer
#endif
#define GFP_ZONE_TABLE ( \
(ZONE_NORMAL << 0 * ZONES_SHIFT) \
| (OPT_ZONE_DMA << ___GFP_DMA * ZONES_SHIFT) \
| (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << ___GFP_DMA32 * ZONES_SHIFT) \
| (ZONE_NORMAL << ___GFP_MOVABLE * ZONES_SHIFT) \
| (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * ZONES_SHIFT) \
| (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * ZONES_SHIFT) \
)
/*
* GFP_ZONE_BAD is a bitmap for all combinations of __GFP_DMA, __GFP_DMA32
* __GFP_HIGHMEM and __GFP_MOVABLE that are not permitted. One flag per
* entry starting with bit 0. Bit is set if the combination is not
* allowed.
*/
#define GFP_ZONE_BAD ( \
1 << (___GFP_DMA | ___GFP_HIGHMEM) \
| 1 << (___GFP_DMA | ___GFP_DMA32) \
| 1 << (___GFP_DMA32 | ___GFP_HIGHMEM) \
| 1 << (___GFP_DMA | ___GFP_DMA32 | ___GFP_HIGHMEM) \
| 1 << (___GFP_MOVABLE | ___GFP_HIGHMEM | ___GFP_DMA) \
| 1 << (___GFP_MOVABLE | ___GFP_DMA32 | ___GFP_DMA) \
| 1 << (___GFP_MOVABLE | ___GFP_DMA32 | ___GFP_HIGHMEM) \
| 1 << (___GFP_MOVABLE | ___GFP_DMA32 | ___GFP_DMA | ___GFP_HIGHMEM) \
)
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
int bit = (__force int) (flags & GFP_ZONEMASK);
z = (GFP_ZONE_TABLE >> (bit * ZONES_SHIFT)) &
((1 << ZONES_SHIFT) - 1);
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}
/*
* There is only one page-allocator function, and two main namespaces to
* it. The alloc_page*() variants return 'struct page *' and as such
* can allocate highmem pages, the *get*page*() variants return
* virtual kernel addresses to the allocated page(s).
*/
static inline int gfp_zonelist(gfp_t flags)
{
if (IS_ENABLED(CONFIG_NUMA) && unlikely(flags & __GFP_THISNODE))
return 1;
return 0;
}
/*
* We get the zone list from the current node and the gfp_mask.
* This zone list contains a maximum of MAXNODES*MAX_NR_ZONES zones.
* There are two zonelists per node, one for all zones with memory and
* one containing just zones from the node the zonelist belongs to.
*
* For the normal case of non-DISCONTIGMEM systems the NODE_DATA() gets
* optimized to &contig_page_data at compile-time.
*/
static inline struct zonelist *node_zonelist(int nid, gfp_t flags)
{
return NODE_DATA(nid)->node_zonelists + gfp_zonelist(flags);
}
#ifndef HAVE_ARCH_FREE_PAGE
static inline void arch_free_page(struct page *page, int order) { }
#endif
#ifndef HAVE_ARCH_ALLOC_PAGE
static inline void arch_alloc_page(struct page *page, int order) { }
#endif
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask);
static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist)
{
return __alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);
}
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
/* Unknown node is current node */
if (nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
static inline struct page *alloc_pages_exact_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES || !node_online(nid));
return __alloc_pages(gfp_mask, order, node_zonelist(nid, gfp_mask));
}
#ifdef CONFIG_NUMA
extern struct page *alloc_pages_current(gfp_t gfp_mask, unsigned order);
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
extern struct page *alloc_pages_vma(gfp_t gfp_mask, int order,
struct vm_area_struct *vma, unsigned long addr,
int node);
#else
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#define alloc_pages_vma(gfp_mask, order, vma, addr, node) \
alloc_pages(gfp_mask, order)
#endif
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
#define alloc_page_vma(gfp_mask, vma, addr) \
alloc_pages_vma(gfp_mask, 0, vma, addr, numa_node_id())
#define alloc_page_vma_node(gfp_mask, vma, addr, node) \
alloc_pages_vma(gfp_mask, 0, vma, addr, node)
extern unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
extern unsigned long get_zeroed_page(gfp_t gfp_mask);
void *alloc_pages_exact(size_t size, gfp_t gfp_mask);
void free_pages_exact(void *virt, size_t size);
/* This is different from alloc_pages_exact_node !!! */
void *alloc_pages_exact_nid(int nid, size_t size, gfp_t gfp_mask);
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask), 0)
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA, (order))
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);
extern void free_hot_cold_page(struct page *page, int cold);
extern void free_hot_cold_page_list(struct list_head *list, int cold);
extern void __free_memcg_kmem_pages(struct page *page, unsigned int order);
extern void free_memcg_kmem_pages(unsigned long addr, unsigned int order);
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)
void page_alloc_init(void);
void drain_zone_pages(struct zone *zone, struct per_cpu_pages *pcp);
void drain_all_pages(void);
void drain_local_pages(void *dummy);
/*
* gfp_allowed_mask is set to GFP_BOOT_MASK during early boot to restrict what
* GFP flags are used before interrupts are enabled. Once interrupts are
* enabled, it is set to __GFP_BITS_MASK while the system is running. During
* hibernation, it is used by PM to avoid I/O during memory allocation while
* devices are suspended.
*/
extern gfp_t gfp_allowed_mask;
/* Returns true if the gfp_mask allows use of ALLOC_NO_WATERMARK */
bool gfp_pfmemalloc_allowed(gfp_t gfp_mask);
extern void pm_restrict_gfp_mask(void);
extern void pm_restore_gfp_mask(void);
#ifdef CONFIG_PM_SLEEP
extern bool pm_suspended_storage(void);
#else
static inline bool pm_suspended_storage(void)
{
return false;
}
#endif /* CONFIG_PM_SLEEP */
#ifdef CONFIG_CMA
/* The below functions must be run on a range from a single zone. */
extern int alloc_contig_range(unsigned long start, unsigned long end,
unsigned migratetype);
extern void free_contig_range(unsigned long pfn, unsigned nr_pages);
/* CMA stuff */
extern void init_cma_reserved_pageblock(struct page *page);
#endif
#endif /* __LINUX_GFP_H */
109 112 115 156
GFP_ATOMIC:告诉分配器以原子的方式分配内存,即在内存分配期间不能够引起进程切换(如果内存不够,内核会唤醒一些内核进程来尝试回收一些内存)。这在某些有特殊要求的情况下非常有用,比如我们前面知道的中断上下文和持有自旋锁的上下文中必须使用该掩码来获取内存。另外,该掩码还表明了可以使用紧急情况下的保留内存。
GFP_KERNEL:最常用的内存分配掩码,具体来讲就是在内存分配过程中允许进积切换,可以进行 I/O 操作(比如为得到空闲页,将页面暂时换出到磁盘上),允许执行文件系统操作。
GFP_USER: 用于为用户空间分配内存页,在内存分配过程中允许进程切换
GFP_DMA:告诉分配器只能在ZONE DMA 区分配内存,用于DMA操作。
__ GFP_HIGHMEM:在高端内存区域分配物理内存。
上面的掩码指定了期望的内存区域,但是得到的内存并不一定就在期望的内存区域中。大体的规则如下:
如果指定了_GFP_HIGHMEM,那么分配器优先在 ZONE_HIGHMEM 区域内查找空
闲内存,如果没有,则退到 ZONE NORMAL 区域中查找,如果还是没有,则在ZONE_DMA中查找。
如果指定了GFP_DMA,那么分配器只能在ZONE_DMA区分配内存如果这两个都没有指定,那么分配器默认会在 ZONE_NORMAL 区域内查找空闲内存,如果没有,则退到 ZONE_DMA 区域中查找。
上面的内存分配函数返回的都是管理物理页面的 struct page 对象地址,而我们通常需要的是物理内存在内核中对应的虚拟地址。对于不是高端内存的物理地址,前面我们说过,虚拟地址和它有一个固定的偏移,我们可以通过这个关系很快得到它对应的虚拟地址。但是对于高端内存的虚拟地址的获取就要麻烦一些,内核需要操作页表来建立映射。相关的函数或宏如下。
void *page_address(const struct page *page);
void *kmap(etruct page *page);
void *kmap_atomic(struct page *page);
vold kunmap(etruct page *page);
page_address:只用于非高端内存的虚拟地址的取,参数 page是分配页得到的 struct page对象地址,返回该物理页对应的内核空间虚拟地址。
kmap:用于返回分配的高端或非高端内存的虚拟地址,如果不是高端内存,则内部调用的其实是 page_address,也叫作永久映射,但是不要被其名字所迷惑,内核中用于永引友
久内存射的区城非常小,所以在不使用时,应该尽快解除映射,该函数可能会引起休眠。
kmap_atomic:和 kmap 功能类似,但操作是原子性的,也叫作临时映射。
kunmap:用于解除前面的映射。
这些内存分配API的典型用法如下。
struct page *p;
void *kva;
void *hva;
p = alloc_pages(GFP_KERNEL, 2);
if (!p)
return -ENOMEM;
kva = page_address(p);
...
__free_pages(p,2);
p = alloc_pages(__GFP_HIGHMEM,2);
if (!p)
return -ENOMEM;
...
hva = kmap(p);
......
kunmap(p);
__free_pages(p,2);
这些内存分配都要分两步来完成,即首先获取物理内存页,然后再返回内核的虚拟地址。内核也提供了另外一组合二为一的函数,常见的函数如下。
unsigned long __get_free_pages (gfp_t gfp_mask, unsigned int order);
unsigned long __get_free_page (gfp_t gfp_mask);
unsigned long get_zeroed_page (gfp_t gfp_mask);
void free_pages (unsigned long addr, unsigned int order);
void free_page(unsigned long addr);
__gt_free_pages、__get _free_page 和 get_zeroed_page 分别用于获取 2 的 order 次方页、获取一页和获取清零页,返回值都为对应的内核虚拟地址。gfp_mask 参数和前面讲解的相同,但是需要注意的是,使用这些函数或宏不能在高端内存上分配页面.free_pages 和 free_page 是对应的页释放函数,参数 addr 是分配得到的内核虚拟地址
典型的用法如下。
void *kva;
kva = (void *)__get_free_pages (GFP_KERNEL, 2);
.......
free_pages((unisgned long) kva,2);三、slab分配器
上一节提到的内存分配函数都是按页来进行的,驱动程序通常较少使用如此大的内存,更多的情况是若干个字节,很显然,页分配器不能为此提供较好的支持。于是内核设计出了针对小块内存的分配器—— slab 分配器。slab 分配的工作很复杂,但是原理很简单,主要的设计思想是,首先使用页面分配器预先分配若干个页,然后将这若干页按照一个特定的对象大小进行切分,要获取一个对象,就从这个对象的高速缓存中获取,使用完后,再释放到同样的对象高速缓存中。所以 slab 分配器不仅具有能够管理小块内存的能力,同时也提供类似于高速缓存的作用,使对象的分配和释放变得非常迅速。内核中经常使用的结构对象通常使用这种方式来进行管理,比如我们前面提到的inode,task_struct等。另外,对象的高速缓存还可以自动地动态伸缩,如果当前系统内比较紧张,那么内核会尝试回收一部分没有用到的对象高速缓存,如果短时间需要分配很多的对象而对象高速缓存不够用时,内核会自动增加动态高速缓存。slab 分配器的主要API如下。
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor) (void *));
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
void kmem_cache_destroy(struct kmem_cache * cachep);
kmem_cache_create:用于创建一个高速缓存,第一个参数是该高速缓存的名字,在/proc/slabinfo 文件中可以查看到该信息;第二个参数是对象的大小;第三个参数是 slab内第一个对象的偏移,也就是对齐设置,通常为 0 即可;第四个参数是可选的设置项,用于进一步控制slab分配器,详细的介绍可以参考“include/inux/slab.h”,没有特殊要求可以为 0:最后一个参数是追加新的页到高速缓存中用到的构造函数,通常不需要,头NULL 即可。函数返回高速缓存的结构对象地址。
/*
* Written by Mark Hemment, 1996 (markhe@nextd.demon.co.uk).
*
* (C) SGI 2006, Christoph Lameter
* Cleaned up and restructured to ease the addition of alternative
* implementations of SLAB allocators.
* (C) Linux Foundation 2008-2013
* Unified interface for all slab allocators
*/
#ifndef _LINUX_SLAB_H
#define _LINUX_SLAB_H
#include <linux/gfp.h>
#include <linux/types.h>
#include <linux/workqueue.h>
/*
* Flags to pass to kmem_cache_create().
* The ones marked DEBUG are only valid if CONFIG_SLAB_DEBUG is set.
*/
#define SLAB_DEBUG_FREE 0x00000100UL /* DEBUG: Perform (expensive) checks on free */
#define SLAB_RED_ZONE 0x00000400UL /* DEBUG: Red zone objs in a cache */
#define SLAB_POISON 0x00000800UL /* DEBUG: Poison objects */
#define SLAB_HWCACHE_ALIGN 0x00002000UL /* Align objs on cache lines */
#define SLAB_CACHE_DMA 0x00004000UL /* Use GFP_DMA memory */
#define SLAB_STORE_USER 0x00010000UL /* DEBUG: Store the last owner for bug hunting */
#define SLAB_PANIC 0x00040000UL /* Panic if kmem_cache_create() fails */
/*
* SLAB_DESTROY_BY_RCU - **WARNING** READ THIS!
*
* This delays freeing the SLAB page by a grace period, it does _NOT_
* delay object freeing. This means that if you do kmem_cache_free()
* that memory location is free to be reused at any time. Thus it may
* be possible to see another object there in the same RCU grace period.
*
* This feature only ensures the memory location backing the object
* stays valid, the trick to using this is relying on an independent
* object validation pass. Something like:
*
* rcu_read_lock()
* again:
* obj = lockless_lookup(key);
* if (obj) {
* if (!try_get_ref(obj)) // might fail for free objects
* goto again;
*
* if (obj->key != key) { // not the object we expected
* put_ref(obj);
* goto again;
* }
* }
* rcu_read_unlock();
*
* This is useful if we need to approach a kernel structure obliquely,
* from its address obtained without the usual locking. We can lock
* the structure to stabilize it and check it's still at the given address,
* only if we can be sure that the memory has not been meanwhile reused
* for some other kind of object (which our subsystem's lock might corrupt).
*
* rcu_read_lock before reading the address, then rcu_read_unlock after
* taking the spinlock within the structure expected at that address.
*/
#define SLAB_DESTROY_BY_RCU 0x00080000UL /* Defer freeing slabs to RCU */
#define SLAB_MEM_SPREAD 0x00100000UL /* Spread some memory over cpuset */
#define SLAB_TRACE 0x00200000UL /* Trace allocations and frees */
/* Flag to prevent checks on free */
#ifdef CONFIG_DEBUG_OBJECTS
# define SLAB_DEBUG_OBJECTS 0x00400000UL
#else
# define SLAB_DEBUG_OBJECTS 0x00000000UL
#endif
#define SLAB_NOLEAKTRACE 0x00800000UL /* Avoid kmemleak tracing */
/* Don't track use of uninitialized memory */
#ifdef CONFIG_KMEMCHECK
# define SLAB_NOTRACK 0x01000000UL
#else
# define SLAB_NOTRACK 0x00000000UL
#endif
#ifdef CONFIG_FAILSLAB
# define SLAB_FAILSLAB 0x02000000UL /* Fault injection mark */
#else
# define SLAB_FAILSLAB 0x00000000UL
#endif
/* The following flags affect the page allocator grouping pages by mobility */
#define SLAB_RECLAIM_ACCOUNT 0x00020000UL /* Objects are reclaimable */
#define SLAB_TEMPORARY SLAB_RECLAIM_ACCOUNT /* Objects are short-lived */
/*
* ZERO_SIZE_PTR will be returned for zero sized kmalloc requests.
*
* Dereferencing ZERO_SIZE_PTR will lead to a distinct access fault.
*
* ZERO_SIZE_PTR can be passed to kfree though in the same way that NULL can.
* Both make kfree a no-op.
*/
#define ZERO_SIZE_PTR ((void *)16)
#define ZERO_OR_NULL_PTR(x) ((unsigned long)(x) <= \
(unsigned long)ZERO_SIZE_PTR)
#include <linux/kmemleak.h>
struct mem_cgroup;
/*
* struct kmem_cache related prototypes
*/
void __init kmem_cache_init(void);
int slab_is_available(void);
struct kmem_cache *kmem_cache_create(const char *, size_t, size_t,
unsigned long,
void (*)(void *));
struct kmem_cache *
kmem_cache_create_memcg(struct mem_cgroup *, const char *, size_t, size_t,
unsigned long, void (*)(void *), struct kmem_cache *);
void kmem_cache_destroy(struct kmem_cache *);
int kmem_cache_shrink(struct kmem_cache *);
void kmem_cache_free(struct kmem_cache *, void *);
/*
* Please use this macro to create slab caches. Simply specify the
* name of the structure and maybe some flags that are listed above.
*
* The alignment of the struct determines object alignment. If you
* f.e. add ____cacheline_aligned_in_smp to the struct declaration
* then the objects will be properly aligned in SMP configurations.
*/
#define KMEM_CACHE(__struct, __flags) kmem_cache_create(#__struct,\
sizeof(struct __struct), __alignof__(struct __struct),\
(__flags), NULL)
/*
* Common kmalloc functions provided by all allocators
*/
void * __must_check __krealloc(const void *, size_t, gfp_t);
void * __must_check krealloc(const void *, size_t, gfp_t);
void kfree(const void *);
void kzfree(const void *);
size_t ksize(const void *);
/*
* Some archs want to perform DMA into kmalloc caches and need a guaranteed
* alignment larger than the alignment of a 64-bit integer.
* Setting ARCH_KMALLOC_MINALIGN in arch headers allows that.
*/
#if defined(ARCH_DMA_MINALIGN) && ARCH_DMA_MINALIGN > 8
#define ARCH_KMALLOC_MINALIGN ARCH_DMA_MINALIGN
#define KMALLOC_MIN_SIZE ARCH_DMA_MINALIGN
#define KMALLOC_SHIFT_LOW ilog2(ARCH_DMA_MINALIGN)
#else
#define ARCH_KMALLOC_MINALIGN __alignof__(unsigned long long)
#endif
#ifdef CONFIG_SLOB
/*
* Common fields provided in kmem_cache by all slab allocators
* This struct is either used directly by the allocator (SLOB)
* or the allocator must include definitions for all fields
* provided in kmem_cache_common in their definition of kmem_cache.
*
* Once we can do anonymous structs (C11 standard) we could put a
* anonymous struct definition in these allocators so that the
* separate allocations in the kmem_cache structure of SLAB and
* SLUB is no longer needed.
*/
struct kmem_cache {
unsigned int object_size;/* The original size of the object */
unsigned int size; /* The aligned/padded/added on size */
unsigned int align; /* Alignment as calculated */
unsigned long flags; /* Active flags on the slab */
const char *name; /* Slab name for sysfs */
int refcount; /* Use counter */
void (*ctor)(void *); /* Called on object slot creation */
struct list_head list; /* List of all slab caches on the system */
};
#endif /* CONFIG_SLOB */
/*
* Kmalloc array related definitions
*/
#ifdef CONFIG_SLAB
/*
* The largest kmalloc size supported by the SLAB allocators is
* 32 megabyte (2^25) or the maximum allocatable page order if that is
* less than 32 MB.
*
* WARNING: Its not easy to increase this value since the allocators have
* to do various tricks to work around compiler limitations in order to
* ensure proper constant folding.
*/
#define KMALLOC_SHIFT_HIGH ((MAX_ORDER + PAGE_SHIFT - 1) <= 25 ? \
(MAX_ORDER + PAGE_SHIFT - 1) : 25)
#define KMALLOC_SHIFT_MAX KMALLOC_SHIFT_HIGH
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 5
#endif
#endif
#ifdef CONFIG_SLUB
/*
* SLUB directly allocates requests fitting in to an order-1 page
* (PAGE_SIZE*2). Larger requests are passed to the page allocator.
*/
#define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1)
#define KMALLOC_SHIFT_MAX (MAX_ORDER + PAGE_SHIFT)
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 3
#endif
#endif
#ifdef CONFIG_SLOB
/*
* SLOB passes all requests larger than one page to the page allocator.
* No kmalloc array is necessary since objects of different sizes can
* be allocated from the same page.
*/
#define KMALLOC_SHIFT_HIGH PAGE_SHIFT
#define KMALLOC_SHIFT_MAX 30
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 3
#endif
#endif
/* Maximum allocatable size */
#define KMALLOC_MAX_SIZE (1UL << KMALLOC_SHIFT_MAX)
/* Maximum size for which we actually use a slab cache */
#define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
/* Maximum order allocatable via the slab allocagtor */
#define KMALLOC_MAX_ORDER (KMALLOC_SHIFT_MAX - PAGE_SHIFT)
/*
* Kmalloc subsystem.
*/
#ifndef KMALLOC_MIN_SIZE
#define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW)
#endif
#ifndef CONFIG_SLOB
extern struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1];
#ifdef CONFIG_ZONE_DMA
extern struct kmem_cache *kmalloc_dma_caches[KMALLOC_SHIFT_HIGH + 1];
#endif
/*
* Figure out which kmalloc slab an allocation of a certain size
* belongs to.
* 0 = zero alloc
* 1 = 65 .. 96 bytes
* 2 = 120 .. 192 bytes
* n = 2^(n-1) .. 2^n -1
*/
static __always_inline int kmalloc_index(size_t size)
{
if (!size)
return 0;
if (size <= KMALLOC_MIN_SIZE)
return KMALLOC_SHIFT_LOW;
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
if (size <= 64) return 6;
if (size <= 128) return 7;
if (size <= 256) return 8;
if (size <= 512) return 9;
if (size <= 1024) return 10;
if (size <= 2 * 1024) return 11;
if (size <= 4 * 1024) return 12;
if (size <= 8 * 1024) return 13;
if (size <= 16 * 1024) return 14;
if (size <= 32 * 1024) return 15;
if (size <= 64 * 1024) return 16;
if (size <= 128 * 1024) return 17;
if (size <= 256 * 1024) return 18;
if (size <= 512 * 1024) return 19;
if (size <= 1024 * 1024) return 20;
if (size <= 2 * 1024 * 1024) return 21;
if (size <= 4 * 1024 * 1024) return 22;
if (size <= 8 * 1024 * 1024) return 23;
if (size <= 16 * 1024 * 1024) return 24;
if (size <= 32 * 1024 * 1024) return 25;
if (size <= 64 * 1024 * 1024) return 26;
BUG();
/* Will never be reached. Needed because the compiler may complain */
return -1;
}
#endif /* !CONFIG_SLOB */
void *__kmalloc(size_t size, gfp_t flags);
void *kmem_cache_alloc(struct kmem_cache *, gfp_t flags);
#ifdef CONFIG_NUMA
void *__kmalloc_node(size_t size, gfp_t flags, int node);
void *kmem_cache_alloc_node(struct kmem_cache *, gfp_t flags, int node);
#else
static __always_inline void *__kmalloc_node(size_t size, gfp_t flags, int node)
{
return __kmalloc(size, flags);
}
static __always_inline void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t flags, int node)
{
return kmem_cache_alloc(s, flags);
}
#endif
#ifdef CONFIG_TRACING
extern void *kmem_cache_alloc_trace(struct kmem_cache *, gfp_t, size_t);
#ifdef CONFIG_NUMA
extern void *kmem_cache_alloc_node_trace(struct kmem_cache *s,
gfp_t gfpflags,
int node, size_t size);
#else
static __always_inline void *
kmem_cache_alloc_node_trace(struct kmem_cache *s,
gfp_t gfpflags,
int node, size_t size)
{
return kmem_cache_alloc_trace(s, gfpflags, size);
}
#endif /* CONFIG_NUMA */
#else /* CONFIG_TRACING */
static __always_inline void *kmem_cache_alloc_trace(struct kmem_cache *s,
gfp_t flags, size_t size)
{
return kmem_cache_alloc(s, flags);
}
static __always_inline void *
kmem_cache_alloc_node_trace(struct kmem_cache *s,
gfp_t gfpflags,
int node, size_t size)
{
return kmem_cache_alloc_node(s, gfpflags, node);
}
#endif /* CONFIG_TRACING */
#ifdef CONFIG_SLAB
#include <linux/slab_def.h>
#endif
#ifdef CONFIG_SLUB
#include <linux/slub_def.h>
#endif
static __always_inline void *
kmalloc_order(size_t size, gfp_t flags, unsigned int order)
{
void *ret;
flags |= (__GFP_COMP | __GFP_KMEMCG);
ret = (void *) __get_free_pages(flags, order);
kmemleak_alloc(ret, size, 1, flags);
return ret;
}
#ifdef CONFIG_TRACING
extern void *kmalloc_order_trace(size_t size, gfp_t flags, unsigned int order);
#else
static __always_inline void *
kmalloc_order_trace(size_t size, gfp_t flags, unsigned int order)
{
return kmalloc_order(size, flags, order);
}
#endif
static __always_inline void *kmalloc_large(size_t size, gfp_t flags)
{
unsigned int order = get_order(size);
return kmalloc_order_trace(size, flags, order);
}
/**
* kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate.
*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
*
* The @flags argument may be one of:
*
* %GFP_USER - Allocate memory on behalf of user. May sleep.
*
* %GFP_KERNEL - Allocate normal kernel ram. May sleep.
*
* %GFP_ATOMIC - Allocation will not sleep. May use emergency pools.
* For example, use this inside interrupt handlers.
*
* %GFP_HIGHUSER - Allocate pages from high memory.
*
* %GFP_NOIO - Do not do any I/O at all while trying to get memory.
*
* %GFP_NOFS - Do not make any fs calls while trying to get memory.
*
* %GFP_NOWAIT - Allocation will not sleep.
*
* %__GFP_THISNODE - Allocate node-local memory only.
*
* %GFP_DMA - Allocation suitable for DMA.
* Should only be used for kmalloc() caches. Otherwise, use a
* slab created with SLAB_DMA.
*
* Also it is possible to set different flags by OR'ing
* in one or more of the following additional @flags:
*
* %__GFP_COLD - Request cache-cold pages instead of
* trying to return cache-warm pages.
*
* %__GFP_HIGH - This allocation has high priority and may use emergency pools.
*
* %__GFP_NOFAIL - Indicate that this allocation is in no way allowed to fail
* (think twice before using).
*
* %__GFP_NORETRY - If memory is not immediately available,
* then give up at once.
*
* %__GFP_NOWARN - If allocation fails, don't issue any warnings.
*
* %__GFP_REPEAT - If allocation fails initially, try once more before failing.
*
* There are other flags available as well, but these are not intended
* for general use, and so are not documented here. For a full list of
* potential flags, always refer to linux/gfp.h.
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
#endif
}
return __kmalloc(size, flags);
}
/*
* Determine size used for the nth kmalloc cache.
* return size or 0 if a kmalloc cache for that
* size does not exist
*/
static __always_inline int kmalloc_size(int n)
{
#ifndef CONFIG_SLOB
if (n > 2)
return 1 << n;
if (n == 1 && KMALLOC_MIN_SIZE <= 32)
return 96;
if (n == 2 && KMALLOC_MIN_SIZE <= 64)
return 192;
#endif
return 0;
}
static __always_inline void *kmalloc_node(size_t size, gfp_t flags, int node)
{
#ifndef CONFIG_SLOB
if (__builtin_constant_p(size) &&
size <= KMALLOC_MAX_CACHE_SIZE && !(flags & GFP_DMA)) {
int i = kmalloc_index(size);
if (!i)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_node_trace(kmalloc_caches[i],
flags, node, size);
}
#endif
return __kmalloc_node(size, flags, node);
}
/*
* Setting ARCH_SLAB_MINALIGN in arch headers allows a different alignment.
* Intended for arches that get misalignment faults even for 64 bit integer
* aligned buffers.
*/
#ifndef ARCH_SLAB_MINALIGN
#define ARCH_SLAB_MINALIGN __alignof__(unsigned long long)
#endif
/*
* This is the main placeholder for memcg-related information in kmem caches.
* struct kmem_cache will hold a pointer to it, so the memory cost while
* disabled is 1 pointer. The runtime cost while enabled, gets bigger than it
* would otherwise be if that would be bundled in kmem_cache: we'll need an
* extra pointer chase. But the trade off clearly lays in favor of not
* penalizing non-users.
*
* Both the root cache and the child caches will have it. For the root cache,
* this will hold a dynamically allocated array large enough to hold
* information about the currently limited memcgs in the system. To allow the
* array to be accessed without taking any locks, on relocation we free the old
* version only after a grace period.
*
* Child caches will hold extra metadata needed for its operation. Fields are:
*
* @memcg: pointer to the memcg this cache belongs to
* @list: list_head for the list of all caches in this memcg
* @root_cache: pointer to the global, root cache, this cache was derived from
* @dead: set to true after the memcg dies; the cache may still be around.
* @nr_pages: number of pages that belongs to this cache.
* @destroy: worker to be called whenever we are ready, or believe we may be
* ready, to destroy this cache.
*/
struct memcg_cache_params {
bool is_root_cache;
union {
struct {
struct rcu_head rcu_head;
struct kmem_cache *memcg_caches[0];
};
struct {
struct mem_cgroup *memcg;
struct list_head list;
struct kmem_cache *root_cache;
bool dead;
atomic_t nr_pages;
struct work_struct destroy;
};
};
};
int memcg_update_all_caches(int num_memcgs);
struct seq_file;
int cache_show(struct kmem_cache *s, struct seq_file *m);
void print_slabinfo_header(struct seq_file *m);
/**
* kmalloc_array - allocate memory for an array.
* @n: number of elements.
* @size: element size.
* @flags: the type of memory to allocate (see kmalloc).
*/
static inline void *kmalloc_array(size_t n, size_t size, gfp_t flags)
{
if (size != 0 && n > SIZE_MAX / size)
return NULL;
return __kmalloc(n * size, flags);
}
/**
* kcalloc - allocate memory for an array. The memory is set to zero.
* @n: number of elements.
* @size: element size.
* @flags: the type of memory to allocate (see kmalloc).
*/
static inline void *kcalloc(size_t n, size_t size, gfp_t flags)
{
return kmalloc_array(n, size, flags | __GFP_ZERO);
}
/*
* kmalloc_track_caller is a special version of kmalloc that records the
* calling function of the routine calling it for slab leak tracking instead
* of just the calling function (confusing, eh?).
* It's useful when the call to kmalloc comes from a widely-used standard
* allocator where we care about the real place the memory allocation
* request comes from.
*/
#if defined(CONFIG_DEBUG_SLAB) || defined(CONFIG_SLUB) || \
(defined(CONFIG_SLAB) && defined(CONFIG_TRACING)) || \
(defined(CONFIG_SLOB) && defined(CONFIG_TRACING))
extern void *__kmalloc_track_caller(size_t, gfp_t, unsigned long);
#define kmalloc_track_caller(size, flags) \
__kmalloc_track_caller(size, flags, _RET_IP_)
#else
#define kmalloc_track_caller(size, flags) \
__kmalloc(size, flags)
#endif /* DEBUG_SLAB */
#ifdef CONFIG_NUMA
/*
* kmalloc_node_track_caller is a special version of kmalloc_node that
* records the calling function of the routine calling it for slab leak
* tracking instead of just the calling function (confusing, eh?).
* It's useful when the call to kmalloc_node comes from a widely-used
* standard allocator where we care about the real place the memory
* allocation request comes from.
*/
#if defined(CONFIG_DEBUG_SLAB) || defined(CONFIG_SLUB) || \
(defined(CONFIG_SLAB) && defined(CONFIG_TRACING)) || \
(defined(CONFIG_SLOB) && defined(CONFIG_TRACING))
extern void *__kmalloc_node_track_caller(size_t, gfp_t, int, unsigned long);
#define kmalloc_node_track_caller(size, flags, node) \
__kmalloc_node_track_caller(size, flags, node, \
_RET_IP_)
#else
#define kmalloc_node_track_caller(size, flags, node) \
__kmalloc_node(size, flags, node)
#endif
#else /* CONFIG_NUMA */
#define kmalloc_node_track_caller(size, flags, node) \
kmalloc_track_caller(size, flags)
#endif /* CONFIG_NUMA */
/*
* Shortcuts
*/
static inline void *kmem_cache_zalloc(struct kmem_cache *k, gfp_t flags)
{
return kmem_cache_alloc(k, flags | __GFP_ZERO);
}
/**
* kzalloc - allocate memory. The memory is set to zero.
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate (see kmalloc).
*/
static inline void *kzalloc(size_t size, gfp_t flags)
{
return kmalloc(size, flags | __GFP_ZERO);
}
/**
* kzalloc_node - allocate zeroed memory from a particular memory node.
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate (see kmalloc).
* @node: memory node from which to allocate
*/
static inline void *kzalloc_node(size_t size, gfp_t flags, int node)
{
return kmalloc_node(size, flags | __GFP_ZERO, node);
}
/*
* Determine the size of a slab object
*/
static inline unsigned int kmem_cache_size(struct kmem_cache *s)
{
return s->object_size;
}
void __init kmem_cache_init_late(void);
#endif /* _LINUX_SLAB_H */
kmem_cache_alloc: 从对象高速缓存 cachep 中返回一个对象,flags 是分配的掩码。
kmem_cache_free: 释放一个对象到高速缓存 cachep 中
kmem cache destroy:销毁对象高速缓存。对象高速缓存的一个最简单的示例代码如下。
5 #include <linux/slab.h>
7 struct test {
8 char c;
9 int i;
10};
11
12 static struct kmem_cache *test_cache;
13 static struct test *t;
......
17 test_cache = kmem_cache_create("test_cache", sizeof(struct test), 0, 0,NULL0;
18 if (!test_cache)
19 return -ENOMEM;
......
21 t = kmem_cache_alloc(test_cache, GFP_KERNEL);
22 if (!t)
23 return -ENOMEM;
......
32 kmem_cache_free(test_cache, t);
33 kmem_cache_destroy(test_cache);
代码第 7行到第 10行是需要经常动态分配的对象的结构类型定义,代码第17 行调用 kmem_cache_create 创建对象高速缓存,名字是 test_cache,每个对象的大小是sizeof(struct test),这通常在模块初始化函数中进行。代码第 21 行,在需要使用对象时使用 kmem_cache_alloc 来分配一个对象,在不需要使用该对象时通过 kmem_cache_free 来释放(代码第32行),当不需要整个对象高速缓存的时候,使用 kmem_cache_destroy 来销毁对象高速缓存 (代码第 33 行),这通常在模块清除函数中进行。
上面的 API可以快速获取和释放一个若干字节的对象,但是在驱动中更多的是像在应用程序中使用 malloc 和 free 一样,来简单、快速分配和释放若干个字节,为此内核专门创建了一些常见字节大小的对象高速缓存。通过下面的命令会很清楚地看到这点。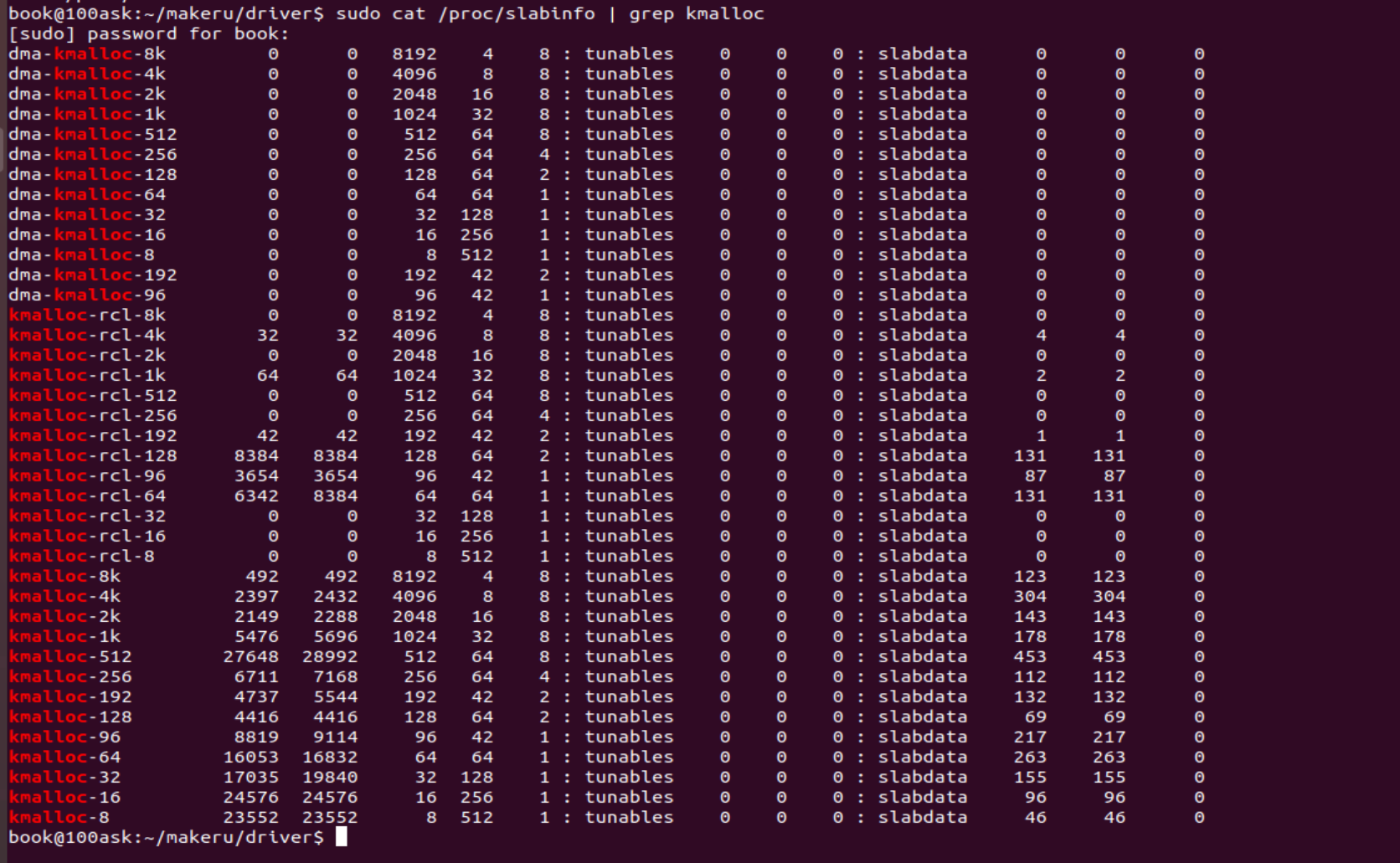
内核被预先创建了很多8字节、16字节等大小的对象高速缓存,我们可以使用一组更简单的函数来分配和释放这些对象。
void *kmalloc(size_t size, gfp_t flags);
void *kzalloc(size_t size, gfp_t flags);
void kfree(const void *);
kmalloc :类似于 malloc,参数 size 指定了要分配内存的大小,不一定必须是 8、16等,比如size 的值为13,那么内核会分配一个 16 字节大小的内存。这看上去虽然有点浪费,但是为了内存管理的简单性和高效性,这样做还是值得的。参数 flags 是分配掩码.函数返回内存的内核虚拟地址,NULL 表示失败。
kzalloc:同kmalloc,只是分配的内存预先被清零
kfree:释放由 kmalloc 分配的内存。
这三个函数是驱动中使用得最多的内存分配函数,可以满足绝大多数情况的需要使用方法也非常简单,在没有特殊要求时推荐使用。
四、不连续内存页分配
内存分配函数都能保证所分配的内存在物理地址空间是连续的,但是这个特点使得想要分配大块的内存变得困难(能够分配的最大页数视不同的系统而定,order 最大的值可能为 12)因为频繁的分配和释放将会导致碎片的产生,这可能会导致本来有足够多的物理内存可用,但是因为不连续而不能分配的问题(这是由伙伴系统的工作方式决定的).为此内核提供了相应的措施来解决这一问题。
在FS4412 目标板的启动过程中,控制台上会打印如下信息。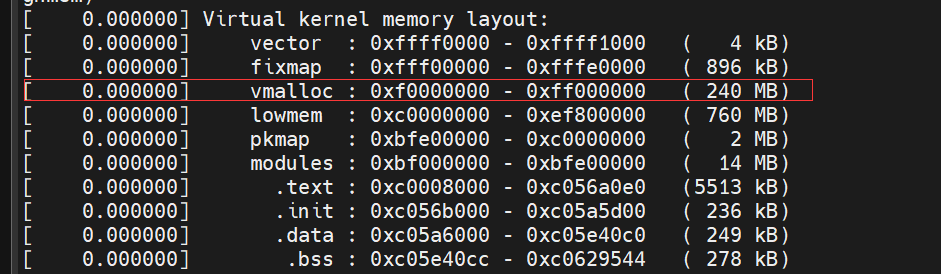
其中,vmalloc就是为解决上面的问题而引入的一部分内核地址空间,通过对页表进行操作,可以把上述空间中的一部分映射到物理地址不连续的页上面。这样可以使连续的内核虚拟地址对应不连续的物理地址,从而可以组合不连续的页,得到较大的内存。当然,因为要操作页表,所以它的工作效率不高,不适合频繁地分配和释放。
不连续内存页分配的主要函数如下。
void *vmalloc(unsigned long size);
void *vzalloc(unsigned long size);
void vfree(const void *addr);
vmalloc和vzalloc 用于分配内存,vzalloc 将分配的内存预先清零,参数size 是要分配内存的大小,返回值为分配的内存虚拟地址,NULL 表示内存分配失败,这两个函数可能会休眠。vfree 释放内存,addr 是要释放的内核虚拟内存地址。
五、per-CPU变量
per-CPU变量就是每个CPU有一个变量的副本,一个典型的用法就是统计各个CPU上的一些信息。例如,每个 CPU 上可以保存一个运行在该 CPU 上的进程的数量,要统计整个系统的进程数,则可以将每个CPU 上的进程数相加。在早期的内核中,通常是用一个数组来实现这一功能的,例如下面的代码。
1 unsigned long pcount[NR_CPUS]-{0};
2
3 int cpu;
5 cpu = get_cpu();
6 pcount[cpu]++;
7 put_cpu();
代码第1行根据CPU的个数静态定义了一个数组,数组中的每一个元素用于记录该CPU上的进程个数,当fork 一个进程时,通过 get_cpu 禁止内核抢占,然后得到CPU的编号,再去索引刚才的那个数组,将对应元素的值自增 1,最后再调用 put_cpu 允许内核抢占。
现在的内核提供了新的方法来定义并使用 per-CPU变量,主要的宏和函数如下。
DEFINE_PER_CPU(type, name)
DECLARE_PER_CPU(type, name)
get_cpu_var(var)
put_cpu_var(var)
per_cpu(var,cpu)
alloc_percpu(type)
void free_percpu(void __percpu * __pdata);
for_each_possible_cpu(cpu)
DEFINE PERCPU:定义一个类型为type名字为name的per-CPU变量.
DECLARE PERCPU:声明在别的地方定义的per-CPU变量
get_cpu_var: 禁止内核抢占,获得当前处理器上的变量 var。
put_cpu_var: 重新使能内核抢占。
per_cpu_var: 获歌其他 cpu 上的变量 var。
alloc_percpu:动态分配一个类型为type的perCPU变量
free_percpu:释放动态分配的perCPU 变量。
for_each_possible_cpu: 遍历每一个可能的CPU,cpu是获得的CPU编号。
在“kernel/fork.c”文件中有一个统计总进程数的函数,该函数可以较好地说明per-CPU 变量的使用。
/*
* linux/kernel/fork.c
*
* Copyright (C) 1991, 1992 Linus Torvalds
*/
/*
* 'fork.c' contains the help-routines for the 'fork' system call
* (see also entry.S and others).
* Fork is rather simple, once you get the hang of it, but the memory
* management can be a bitch. See 'mm/memory.c': 'copy_page_range()'
*/
#include <linux/slab.h>
#include <linux/init.h>
#include <linux/unistd.h>
#include <linux/module.h>
#include <linux/vmalloc.h>
#include <linux/completion.h>
#include <linux/personality.h>
#include <linux/mempolicy.h>
#include <linux/sem.h>
#include <linux/file.h>
#include <linux/fdtable.h>
#include <linux/iocontext.h>
#include <linux/key.h>
#include <linux/binfmts.h>
#include <linux/mman.h>
#include <linux/mmu_notifier.h>
#include <linux/fs.h>
#include <linux/nsproxy.h>
#include <linux/capability.h>
#include <linux/cpu.h>
#include <linux/cgroup.h>
#include <linux/security.h>
#include <linux/hugetlb.h>
#include <linux/seccomp.h>
#include <linux/swap.h>
#include <linux/syscalls.h>
#include <linux/jiffies.h>
#include <linux/futex.h>
#include <linux/compat.h>
#include <linux/kthread.h>
#include <linux/task_io_accounting_ops.h>
#include <linux/rcupdate.h>
#include <linux/ptrace.h>
#include <linux/mount.h>
#include <linux/audit.h>
#include <linux/memcontrol.h>
#include <linux/ftrace.h>
#include <linux/proc_fs.h>
#include <linux/profile.h>
#include <linux/rmap.h>
#include <linux/ksm.h>
#include <linux/acct.h>
#include <linux/tsacct_kern.h>
#include <linux/cn_proc.h>
#include <linux/freezer.h>
#include <linux/delayacct.h>
#include <linux/taskstats_kern.h>
#include <linux/random.h>
#include <linux/tty.h>
#include <linux/blkdev.h>
#include <linux/fs_struct.h>
#include <linux/magic.h>
#include <linux/perf_event.h>
#include <linux/posix-timers.h>
#include <linux/user-return-notifier.h>
#include <linux/oom.h>
#include <linux/khugepaged.h>
#include <linux/signalfd.h>
#include <linux/uprobes.h>
#include <linux/aio.h>
#include <asm/pgtable.h>
#include <asm/pgalloc.h>
#include <asm/uaccess.h>
#include <asm/mmu_context.h>
#include <asm/cacheflush.h>
#include <asm/tlbflush.h>
#include <trace/events/sched.h>
#define CREATE_TRACE_POINTS
#include <trace/events/task.h>
/*
* Protected counters by write_lock_irq(&tasklist_lock)
*/
unsigned long total_forks; /* Handle normal Linux uptimes. */
int nr_threads; /* The idle threads do not count.. */
int max_threads; /* tunable limit on nr_threads */
DEFINE_PER_CPU(unsigned long, process_counts) = 0;
__cacheline_aligned DEFINE_RWLOCK(tasklist_lock); /* outer */
#ifdef CONFIG_PROVE_RCU
int lockdep_tasklist_lock_is_held(void)
{
return lockdep_is_held(&tasklist_lock);
}
EXPORT_SYMBOL_GPL(lockdep_tasklist_lock_is_held);
#endif /* #ifdef CONFIG_PROVE_RCU */
int nr_processes(void)
{
int cpu;
int total = 0;
for_each_possible_cpu(cpu)
total += per_cpu(process_counts, cpu);
return total;
}
void __weak arch_release_task_struct(struct task_struct *tsk)
{
}
#ifndef CONFIG_ARCH_TASK_STRUCT_ALLOCATOR
static struct kmem_cache *task_struct_cachep;
static inline struct task_struct *alloc_task_struct_node(int node)
{
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
static inline void free_task_struct(struct task_struct *tsk)
{
kmem_cache_free(task_struct_cachep, tsk);
}
#endif
void __weak arch_release_thread_info(struct thread_info *ti)
{
}
#ifndef CONFIG_ARCH_THREAD_INFO_ALLOCATOR
/*
* Allocate pages if THREAD_SIZE is >= PAGE_SIZE, otherwise use a
* kmemcache based allocator.
*/
# if THREAD_SIZE >= PAGE_SIZE
static struct thread_info *alloc_thread_info_node(struct task_struct *tsk,
int node)
{
struct page *page = alloc_pages_node(node, THREADINFO_GFP_ACCOUNTED,
THREAD_SIZE_ORDER);
return page ? page_address(page) : NULL;
}
static inline void free_thread_info(struct thread_info *ti)
{
free_memcg_kmem_pages((unsigned long)ti, THREAD_SIZE_ORDER);
}
# else
static struct kmem_cache *thread_info_cache;
static struct thread_info *alloc_thread_info_node(struct task_struct *tsk,
int node)
{
return kmem_cache_alloc_node(thread_info_cache, THREADINFO_GFP, node);
}
static void free_thread_info(struct thread_info *ti)
{
kmem_cache_free(thread_info_cache, ti);
}
void thread_info_cache_init(void)
{
thread_info_cache = kmem_cache_create("thread_info", THREAD_SIZE,
THREAD_SIZE, 0, NULL);
BUG_ON(thread_info_cache == NULL);
}
# endif
#endif
/* SLAB cache for signal_struct structures (tsk->signal) */
static struct kmem_cache *signal_cachep;
/* SLAB cache for sighand_struct structures (tsk->sighand) */
struct kmem_cache *sighand_cachep;
/* SLAB cache for files_struct structures (tsk->files) */
struct kmem_cache *files_cachep;
/* SLAB cache for fs_struct structures (tsk->fs) */
struct kmem_cache *fs_cachep;
/* SLAB cache for vm_area_struct structures */
struct kmem_cache *vm_area_cachep;
/* SLAB cache for mm_struct structures (tsk->mm) */
static struct kmem_cache *mm_cachep;
static void account_kernel_stack(struct thread_info *ti, int account)
{
struct zone *zone = page_zone(virt_to_page(ti));
mod_zone_page_state(zone, NR_KERNEL_STACK, account);
}
void free_task(struct task_struct *tsk)
{
account_kernel_stack(tsk->stack, -1);
arch_release_thread_info(tsk->stack);
free_thread_info(tsk->stack);
rt_mutex_debug_task_free(tsk);
ftrace_graph_exit_task(tsk);
put_seccomp_filter(tsk);
arch_release_task_struct(tsk);
free_task_struct(tsk);
}
EXPORT_SYMBOL(free_task);
static inline void free_signal_struct(struct signal_struct *sig)
{
taskstats_tgid_free(sig);
sched_autogroup_exit(sig);
kmem_cache_free(signal_cachep, sig);
}
static inline void put_signal_struct(struct signal_struct *sig)
{
if (atomic_dec_and_test(&sig->sigcnt))
free_signal_struct(sig);
}
void __put_task_struct(struct task_struct *tsk)
{
WARN_ON(!tsk->exit_state);
WARN_ON(atomic_read(&tsk->usage));
WARN_ON(tsk == current);
security_task_free(tsk);
exit_creds(tsk);
delayacct_tsk_free(tsk);
put_signal_struct(tsk->signal);
if (!profile_handoff_task(tsk))
free_task(tsk);
}
EXPORT_SYMBOL_GPL(__put_task_struct);
void __init __weak arch_task_cache_init(void) { }
void __init fork_init(unsigned long mempages)
{
#ifndef CONFIG_ARCH_TASK_STRUCT_ALLOCATOR
#ifndef ARCH_MIN_TASKALIGN
#define ARCH_MIN_TASKALIGN L1_CACHE_BYTES
#endif
/* create a slab on which task_structs can be allocated */
task_struct_cachep =
kmem_cache_create("task_struct", sizeof(struct task_struct),
ARCH_MIN_TASKALIGN, SLAB_PANIC | SLAB_NOTRACK, NULL);
#endif
/* do the arch specific task caches init */
arch_task_cache_init();
/*
* The default maximum number of threads is set to a safe
* value: the thread structures can take up at most half
* of memory.
*/
max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE);
/*
* we need to allow at least 20 threads to boot a system
*/
if (max_threads < 20)
max_threads = 20;
init_task.signal->rlim[RLIMIT_NPROC].rlim_cur = max_threads/2;
init_task.signal->rlim[RLIMIT_NPROC].rlim_max = max_threads/2;
init_task.signal->rlim[RLIMIT_SIGPENDING] =
init_task.signal->rlim[RLIMIT_NPROC];
}
int __attribute__((weak)) arch_dup_task_struct(struct task_struct *dst,
struct task_struct *src)
{
*dst = *src;
return 0;
}
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int node = tsk_fork_get_node(orig);
int err;
tsk = alloc_task_struct_node(node);
if (!tsk)
return NULL;
ti = alloc_thread_info_node(tsk, node);
if (!ti)
goto free_tsk;
err = arch_dup_task_struct(tsk, orig);
if (err)
goto free_ti;
tsk->stack = ti;
setup_thread_stack(tsk, orig);
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
/*
* One for us, one for whoever does the "release_task()" (usually
* parent)
*/
atomic_set(&tsk->usage, 2);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
tsk->task_frag.page = NULL;
account_kernel_stack(ti, 1);
return tsk;
free_ti:
free_thread_info(ti);
free_tsk:
free_task_struct(tsk);
return NULL;
}
#ifdef CONFIG_MMU
static int dup_mmap(struct mm_struct *mm, struct mm_struct *oldmm)
{
struct vm_area_struct *mpnt, *tmp, *prev, **pprev;
struct rb_node **rb_link, *rb_parent;
int retval;
unsigned long charge;
uprobe_start_dup_mmap();
down_write(&oldmm->mmap_sem);
flush_cache_dup_mm(oldmm);
uprobe_dup_mmap(oldmm, mm);
/*
* Not linked in yet - no deadlock potential:
*/
down_write_nested(&mm->mmap_sem, SINGLE_DEPTH_NESTING);
mm->locked_vm = 0;
mm->mmap = NULL;
mm->mmap_cache = NULL;
mm->map_count = 0;
cpumask_clear(mm_cpumask(mm));
mm->mm_rb = RB_ROOT;
rb_link = &mm->mm_rb.rb_node;
rb_parent = NULL;
pprev = &mm->mmap;
retval = ksm_fork(mm, oldmm);
if (retval)
goto out;
retval = khugepaged_fork(mm, oldmm);
if (retval)
goto out;
prev = NULL;
for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) {
struct file *file;
if (mpnt->vm_flags & VM_DONTCOPY) {
vm_stat_account(mm, mpnt->vm_flags, mpnt->vm_file,
-vma_pages(mpnt));
continue;
}
charge = 0;
if (mpnt->vm_flags & VM_ACCOUNT) {
unsigned long len = vma_pages(mpnt);
if (security_vm_enough_memory_mm(oldmm, len)) /* sic */
goto fail_nomem;
charge = len;
}
tmp = kmem_cache_alloc(vm_area_cachep, GFP_KERNEL);
if (!tmp)
goto fail_nomem;
*tmp = *mpnt;
INIT_LIST_HEAD(&tmp->anon_vma_chain);
retval = vma_dup_policy(mpnt, tmp);
if (retval)
goto fail_nomem_policy;
tmp->vm_mm = mm;
if (anon_vma_fork(tmp, mpnt))
goto fail_nomem_anon_vma_fork;
tmp->vm_flags &= ~VM_LOCKED;
tmp->vm_next = tmp->vm_prev = NULL;
file = tmp->vm_file;
if (file) {
struct inode *inode = file_inode(file);
struct address_space *mapping = file->f_mapping;
get_file(file);
if (tmp->vm_flags & VM_DENYWRITE)
atomic_dec(&inode->i_writecount);
mutex_lock(&mapping->i_mmap_mutex);
if (tmp->vm_flags & VM_SHARED)
mapping->i_mmap_writable++;
flush_dcache_mmap_lock(mapping);
/* insert tmp into the share list, just after mpnt */
if (unlikely(tmp->vm_flags & VM_NONLINEAR))
vma_nonlinear_insert(tmp,
&mapping->i_mmap_nonlinear);
else
vma_interval_tree_insert_after(tmp, mpnt,
&mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
mutex_unlock(&mapping->i_mmap_mutex);
}
/*
* Clear hugetlb-related page reserves for children. This only
* affects MAP_PRIVATE mappings. Faults generated by the child
* are not guaranteed to succeed, even if read-only
*/
if (is_vm_hugetlb_page(tmp))
reset_vma_resv_huge_pages(tmp);
/*
* Link in the new vma and copy the page table entries.
*/
*pprev = tmp;
pprev = &tmp->vm_next;
tmp->vm_prev = prev;
prev = tmp;
__vma_link_rb(mm, tmp, rb_link, rb_parent);
rb_link = &tmp->vm_rb.rb_right;
rb_parent = &tmp->vm_rb;
mm->map_count++;
retval = copy_page_range(mm, oldmm, mpnt);
if (tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
if (retval)
goto out;
}
/* a new mm has just been created */
arch_dup_mmap(oldmm, mm);
retval = 0;
out:
up_write(&mm->mmap_sem);
flush_tlb_mm(oldmm);
up_write(&oldmm->mmap_sem);
uprobe_end_dup_mmap();
return retval;
fail_nomem_anon_vma_fork:
mpol_put(vma_policy(tmp));
fail_nomem_policy:
kmem_cache_free(vm_area_cachep, tmp);
fail_nomem:
retval = -ENOMEM;
vm_unacct_memory(charge);
goto out;
}
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
mm->pgd = pgd_alloc(mm);
if (unlikely(!mm->pgd))
return -ENOMEM;
return 0;
}
static inline void mm_free_pgd(struct mm_struct *mm)
{
pgd_free(mm, mm->pgd);
}
#else
#define dup_mmap(mm, oldmm) (0)
#define mm_alloc_pgd(mm) (0)
#define mm_free_pgd(mm)
#endif /* CONFIG_MMU */
__cacheline_aligned_in_smp DEFINE_SPINLOCK(mmlist_lock);
#define allocate_mm() (kmem_cache_alloc(mm_cachep, GFP_KERNEL))
#define free_mm(mm) (kmem_cache_free(mm_cachep, (mm)))
static unsigned long default_dump_filter = MMF_DUMP_FILTER_DEFAULT;
static int __init coredump_filter_setup(char *s)
{
default_dump_filter =
(simple_strtoul(s, NULL, 0) << MMF_DUMP_FILTER_SHIFT) &
MMF_DUMP_FILTER_MASK;
return 1;
}
__setup("coredump_filter=", coredump_filter_setup);
#include <linux/init_task.h>
static void mm_init_aio(struct mm_struct *mm)
{
#ifdef CONFIG_AIO
spin_lock_init(&mm->ioctx_lock);
mm->ioctx_table = NULL;
#endif
}
static struct mm_struct *mm_init(struct mm_struct *mm, struct task_struct *p)
{
atomic_set(&mm->mm_users, 1);
atomic_set(&mm->mm_count, 1);
init_rwsem(&mm->mmap_sem);
INIT_LIST_HEAD(&mm->mmlist);
mm->flags = (current->mm) ?
(current->mm->flags & MMF_INIT_MASK) : default_dump_filter;
mm->core_state = NULL;
atomic_long_set(&mm->nr_ptes, 0);
memset(&mm->rss_stat, 0, sizeof(mm->rss_stat));
spin_lock_init(&mm->page_table_lock);
mm_init_aio(mm);
mm_init_owner(mm, p);
clear_tlb_flush_pending(mm);
if (likely(!mm_alloc_pgd(mm))) {
mm->def_flags = 0;
mmu_notifier_mm_init(mm);
return mm;
}
free_mm(mm);
return NULL;
}
static void check_mm(struct mm_struct *mm)
{
int i;
for (i = 0; i < NR_MM_COUNTERS; i++) {
long x = atomic_long_read(&mm->rss_stat.count[i]);
if (unlikely(x))
printk(KERN_ALERT "BUG: Bad rss-counter state "
"mm:%p idx:%d val:%ld\n", mm, i, x);
}
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
VM_BUG_ON(mm->pmd_huge_pte);
#endif
}
/*
* Allocate and initialize an mm_struct.
*/
struct mm_struct *mm_alloc(void)
{
struct mm_struct *mm;
mm = allocate_mm();
if (!mm)
return NULL;
memset(mm, 0, sizeof(*mm));
mm_init_cpumask(mm);
return mm_init(mm, current);
}
/*
* Called when the last reference to the mm
* is dropped: either by a lazy thread or by
* mmput. Free the page directory and the mm.
*/
void __mmdrop(struct mm_struct *mm)
{
BUG_ON(mm == &init_mm);
mm_free_pgd(mm);
destroy_context(mm);
mmu_notifier_mm_destroy(mm);
check_mm(mm);
free_mm(mm);
}
EXPORT_SYMBOL_GPL(__mmdrop);
/*
* Decrement the use count and release all resources for an mm.
*/
void mmput(struct mm_struct *mm)
{
might_sleep();
if (atomic_dec_and_test(&mm->mm_users)) {
uprobe_clear_state(mm);
exit_aio(mm);
ksm_exit(mm);
khugepaged_exit(mm); /* must run before exit_mmap */
exit_mmap(mm);
set_mm_exe_file(mm, NULL);
if (!list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
list_del(&mm->mmlist);
spin_unlock(&mmlist_lock);
}
if (mm->binfmt)
module_put(mm->binfmt->module);
mmdrop(mm);
}
}
EXPORT_SYMBOL_GPL(mmput);
void set_mm_exe_file(struct mm_struct *mm, struct file *new_exe_file)
{
if (new_exe_file)
get_file(new_exe_file);
if (mm->exe_file)
fput(mm->exe_file);
mm->exe_file = new_exe_file;
}
struct file *get_mm_exe_file(struct mm_struct *mm)
{
struct file *exe_file;
/* We need mmap_sem to protect against races with removal of exe_file */
down_read(&mm->mmap_sem);
exe_file = mm->exe_file;
if (exe_file)
get_file(exe_file);
up_read(&mm->mmap_sem);
return exe_file;
}
static void dup_mm_exe_file(struct mm_struct *oldmm, struct mm_struct *newmm)
{
/* It's safe to write the exe_file pointer without exe_file_lock because
* this is called during fork when the task is not yet in /proc */
newmm->exe_file = get_mm_exe_file(oldmm);
}
/**
* get_task_mm - acquire a reference to the task's mm
*
* Returns %NULL if the task has no mm. Checks PF_KTHREAD (meaning
* this kernel workthread has transiently adopted a user mm with use_mm,
* to do its AIO) is not set and if so returns a reference to it, after
* bumping up the use count. User must release the mm via mmput()
* after use. Typically used by /proc and ptrace.
*/
struct mm_struct *get_task_mm(struct task_struct *task)
{
struct mm_struct *mm;
task_lock(task);
mm = task->mm;
if (mm) {
if (task->flags & PF_KTHREAD)
mm = NULL;
else
atomic_inc(&mm->mm_users);
}
task_unlock(task);
return mm;
}
EXPORT_SYMBOL_GPL(get_task_mm);
struct mm_struct *mm_access(struct task_struct *task, unsigned int mode)
{
struct mm_struct *mm;
int err;
err = mutex_lock_killable(&task->signal->cred_guard_mutex);
if (err)
return ERR_PTR(err);
mm = get_task_mm(task);
if (mm && mm != current->mm &&
!ptrace_may_access(task, mode)) {
mmput(mm);
mm = ERR_PTR(-EACCES);
}
mutex_unlock(&task->signal->cred_guard_mutex);
return mm;
}
static void complete_vfork_done(struct task_struct *tsk)
{
struct completion *vfork;
task_lock(tsk);
vfork = tsk->vfork_done;
if (likely(vfork)) {
tsk->vfork_done = NULL;
complete(vfork);
}
task_unlock(tsk);
}
static int wait_for_vfork_done(struct task_struct *child,
struct completion *vfork)
{
int killed;
freezer_do_not_count();
killed = wait_for_completion_killable(vfork);
freezer_count();
if (killed) {
task_lock(child);
child->vfork_done = NULL;
task_unlock(child);
}
put_task_struct(child);
return killed;
}
/* Please note the differences between mmput and mm_release.
* mmput is called whenever we stop holding onto a mm_struct,
* error success whatever.
*
* mm_release is called after a mm_struct has been removed
* from the current process.
*
* This difference is important for error handling, when we
* only half set up a mm_struct for a new process and need to restore
* the old one. Because we mmput the new mm_struct before
* restoring the old one. . .
* Eric Biederman 10 January 1998
*/
void mm_release(struct task_struct *tsk, struct mm_struct *mm)
{
/* Get rid of any futexes when releasing the mm */
#ifdef CONFIG_FUTEX
if (unlikely(tsk->robust_list)) {
exit_robust_list(tsk);
tsk->robust_list = NULL;
}
#ifdef CONFIG_COMPAT
if (unlikely(tsk->compat_robust_list)) {
compat_exit_robust_list(tsk);
tsk->compat_robust_list = NULL;
}
#endif
if (unlikely(!list_empty(&tsk->pi_state_list)))
exit_pi_state_list(tsk);
#endif
uprobe_free_utask(tsk);
/* Get rid of any cached register state */
deactivate_mm(tsk, mm);
/*
* If we're exiting normally, clear a user-space tid field if
* requested. We leave this alone when dying by signal, to leave
* the value intact in a core dump, and to save the unnecessary
* trouble, say, a killed vfork parent shouldn't touch this mm.
* Userland only wants this done for a sys_exit.
*/
if (tsk->clear_child_tid) {
if (!(tsk->flags & PF_SIGNALED) &&
atomic_read(&mm->mm_users) > 1) {
/*
* We don't check the error code - if userspace has
* not set up a proper pointer then tough luck.
*/
put_user(0, tsk->clear_child_tid);
sys_futex(tsk->clear_child_tid, FUTEX_WAKE,
1, NULL, NULL, 0);
}
tsk->clear_child_tid = NULL;
}
/*
* All done, finally we can wake up parent and return this mm to him.
* Also kthread_stop() uses this completion for synchronization.
*/
if (tsk->vfork_done)
complete_vfork_done(tsk);
}
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
int err;
mm = allocate_mm();
if (!mm)
goto fail_nomem;
memcpy(mm, oldmm, sizeof(*mm));
mm_init_cpumask(mm);
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
mm->pmd_huge_pte = NULL;
#endif
if (!mm_init(mm, tsk))
goto fail_nomem;
if (init_new_context(tsk, mm))
goto fail_nocontext;
dup_mm_exe_file(oldmm, mm);
err = dup_mmap(mm, oldmm);
if (err)
goto free_pt;
mm->hiwater_rss = get_mm_rss(mm);
mm->hiwater_vm = mm->total_vm;
if (mm->binfmt && !try_module_get(mm->binfmt->module))
goto free_pt;
return mm;
free_pt:
/* don't put binfmt in mmput, we haven't got module yet */
mm->binfmt = NULL;
mmput(mm);
fail_nomem:
return NULL;
fail_nocontext:
/*
* If init_new_context() failed, we cannot use mmput() to free the mm
* because it calls destroy_context()
*/
mm_free_pgd(mm);
free_mm(mm);
return NULL;
}
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
#ifdef CONFIG_DETECT_HUNG_TASK
tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
#endif
tsk->mm = NULL;
tsk->active_mm = NULL;
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm;
if (!oldmm)
return 0;
if (clone_flags & CLONE_VM) {
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{
struct fs_struct *fs = current->fs;
if (clone_flags & CLONE_FS) {
/* tsk->fs is already what we want */
spin_lock(&fs->lock);
if (fs->in_exec) {
spin_unlock(&fs->lock);
return -EAGAIN;
}
fs->users++;
spin_unlock(&fs->lock);
return 0;
}
tsk->fs = copy_fs_struct(fs);
if (!tsk->fs)
return -ENOMEM;
return 0;
}
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
int error = 0;
/*
* A background process may not have any files ...
*/
oldf = current->files;
if (!oldf)
goto out;
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
newf = dup_fd(oldf, &error);
if (!newf)
goto out;
tsk->files = newf;
error = 0;
out:
return error;
}
static int copy_io(unsigned long clone_flags, struct task_struct *tsk)
{
#ifdef CONFIG_BLOCK
struct io_context *ioc = current->io_context;
struct io_context *new_ioc;
if (!ioc)
return 0;
/*
* Share io context with parent, if CLONE_IO is set
*/
if (clone_flags & CLONE_IO) {
ioc_task_link(ioc);
tsk->io_context = ioc;
} else if (ioprio_valid(ioc->ioprio)) {
new_ioc = get_task_io_context(tsk, GFP_KERNEL, NUMA_NO_NODE);
if (unlikely(!new_ioc))
return -ENOMEM;
new_ioc->ioprio = ioc->ioprio;
put_io_context(new_ioc);
}
#endif
return 0;
}
static int copy_sighand(unsigned long clone_flags, struct task_struct *tsk)
{
struct sighand_struct *sig;
if (clone_flags & CLONE_SIGHAND) {
atomic_inc(¤t->sighand->count);
return 0;
}
sig = kmem_cache_alloc(sighand_cachep, GFP_KERNEL);
rcu_assign_pointer(tsk->sighand, sig);
if (!sig)
return -ENOMEM;
atomic_set(&sig->count, 1);
memcpy(sig->action, current->sighand->action, sizeof(sig->action));
return 0;
}
void __cleanup_sighand(struct sighand_struct *sighand)
{
if (atomic_dec_and_test(&sighand->count)) {
signalfd_cleanup(sighand);
kmem_cache_free(sighand_cachep, sighand);
}
}
/*
* Initialize POSIX timer handling for a thread group.
*/
static void posix_cpu_timers_init_group(struct signal_struct *sig)
{
unsigned long cpu_limit;
/* Thread group counters. */
thread_group_cputime_init(sig);
cpu_limit = ACCESS_ONCE(sig->rlim[RLIMIT_CPU].rlim_cur);
if (cpu_limit != RLIM_INFINITY) {
sig->cputime_expires.prof_exp = secs_to_cputime(cpu_limit);
sig->cputimer.running = 1;
}
/* The timer lists. */
INIT_LIST_HEAD(&sig->cpu_timers[0]);
INIT_LIST_HEAD(&sig->cpu_timers[1]);
INIT_LIST_HEAD(&sig->cpu_timers[2]);
}
static int copy_signal(unsigned long clone_flags, struct task_struct *tsk)
{
struct signal_struct *sig;
if (clone_flags & CLONE_THREAD)
return 0;
sig = kmem_cache_zalloc(signal_cachep, GFP_KERNEL);
tsk->signal = sig;
if (!sig)
return -ENOMEM;
sig->nr_threads = 1;
atomic_set(&sig->live, 1);
atomic_set(&sig->sigcnt, 1);
/* list_add(thread_node, thread_head) without INIT_LIST_HEAD() */
sig->thread_head = (struct list_head)LIST_HEAD_INIT(tsk->thread_node);
tsk->thread_node = (struct list_head)LIST_HEAD_INIT(sig->thread_head);
init_waitqueue_head(&sig->wait_chldexit);
sig->curr_target = tsk;
init_sigpending(&sig->shared_pending);
INIT_LIST_HEAD(&sig->posix_timers);
hrtimer_init(&sig->real_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
sig->real_timer.function = it_real_fn;
task_lock(current->group_leader);
memcpy(sig->rlim, current->signal->rlim, sizeof sig->rlim);
task_unlock(current->group_leader);
posix_cpu_timers_init_group(sig);
tty_audit_fork(sig);
sched_autogroup_fork(sig);
#ifdef CONFIG_CGROUPS
init_rwsem(&sig->group_rwsem);
#endif
sig->oom_score_adj = current->signal->oom_score_adj;
sig->oom_score_adj_min = current->signal->oom_score_adj_min;
sig->has_child_subreaper = current->signal->has_child_subreaper ||
current->signal->is_child_subreaper;
mutex_init(&sig->cred_guard_mutex);
return 0;
}
static void copy_flags(unsigned long clone_flags, struct task_struct *p)
{
unsigned long new_flags = p->flags;
new_flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER);
new_flags |= PF_FORKNOEXEC;
p->flags = new_flags;
}
SYSCALL_DEFINE1(set_tid_address, int __user *, tidptr)
{
current->clear_child_tid = tidptr;
return task_pid_vnr(current);
}
static void rt_mutex_init_task(struct task_struct *p)
{
raw_spin_lock_init(&p->pi_lock);
#ifdef CONFIG_RT_MUTEXES
p->pi_waiters = RB_ROOT;
p->pi_waiters_leftmost = NULL;
p->pi_blocked_on = NULL;
p->pi_top_task = NULL;
#endif
}
#ifdef CONFIG_MM_OWNER
void mm_init_owner(struct mm_struct *mm, struct task_struct *p)
{
mm->owner = p;
}
#endif /* CONFIG_MM_OWNER */
/*
* Initialize POSIX timer handling for a single task.
*/
static void posix_cpu_timers_init(struct task_struct *tsk)
{
tsk->cputime_expires.prof_exp = 0;
tsk->cputime_expires.virt_exp = 0;
tsk->cputime_expires.sched_exp = 0;
INIT_LIST_HEAD(&tsk->cpu_timers[0]);
INIT_LIST_HEAD(&tsk->cpu_timers[1]);
INIT_LIST_HEAD(&tsk->cpu_timers[2]);
}
static inline void
init_task_pid(struct task_struct *task, enum pid_type type, struct pid *pid)
{
task->pids[type].pid = pid;
}
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
/*
* If the new process will be in a different pid or user namespace
* do not allow it to share a thread group or signal handlers or
* parent with the forking task.
*/
if (clone_flags & CLONE_SIGHAND) {
if ((clone_flags & (CLONE_NEWUSER | CLONE_NEWPID)) ||
(task_active_pid_ns(current) !=
current->nsproxy->pid_ns_for_children))
return ERR_PTR(-EINVAL);
}
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
get_seccomp_filter(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = p->stime = p->gtime = 0;
p->utimescaled = p->stimescaled = 0;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE
p->prev_cputime.utime = p->prev_cputime.stime = 0;
#endif
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
seqlock_init(&p->vtime_seqlock);
p->vtime_snap = 0;
p->vtime_snap_whence = VTIME_SLEEPING;
#endif
#if defined(SPLIT_RSS_COUNTING)
memset(&p->rss_stat, 0, sizeof(p->rss_stat));
#endif
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
if (clone_flags & CLONE_THREAD)
threadgroup_change_begin(current);
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_cgroup;
}
mpol_fix_fork_child_flag(p);
#endif
#ifdef CONFIG_CPUSETS
p->cpuset_mem_spread_rotor = NUMA_NO_NODE;
p->cpuset_slab_spread_rotor = NUMA_NO_NODE;
seqcount_init(&p->mems_allowed_seq);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
p->hardirqs_enabled = 0;
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
#ifdef CONFIG_MEMCG
p->memcg_batch.do_batch = 0;
p->memcg_batch.memcg = NULL;
#endif
#ifdef CONFIG_BCACHE
p->sequential_io = 0;
p->sequential_io_avg = 0;
#endif
/* Perform scheduler related setup. Assign this task to a CPU. */
retval = sched_fork(clone_flags, p);
if (retval)
goto bad_fork_cleanup_policy;
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_policy;
/* copy all the process information */
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr : NULL;
#ifdef CONFIG_BLOCK
p->plug = NULL;
#endif
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing and stepping should be turned off in the
* child regardless of CLONE_PTRACE.
*/
user_disable_single_step(p);
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
p->nr_dirtied = 0;
p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10);
p->dirty_paused_when = 0;
p->pdeath_signal = 0;
INIT_LIST_HEAD(&p->thread_group);
p->task_works = NULL;
/*
* Make it visible to the rest of the system, but dont wake it up yet.
* Need tasklist lock for parent etc handling!
*/
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
atomic_inc(¤t->signal->sigcnt);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
perf_event_fork(p);
trace_task_newtask(p, clone_flags);
uprobe_copy_process(p, clone_flags);
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
free_signal_struct(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_cgroup:
#endif
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
cgroup_exit(p, 0);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}
static inline void init_idle_pids(struct pid_link *links)
{
enum pid_type type;
for (type = PIDTYPE_PID; type < PIDTYPE_MAX; ++type) {
INIT_HLIST_NODE(&links[type].node); /* not really needed */
links[type].pid = &init_struct_pid;
}
}
struct task_struct *fork_idle(int cpu)
{
struct task_struct *task;
task = copy_process(CLONE_VM, 0, 0, NULL, &init_struct_pid, 0);
if (!IS_ERR(task)) {
init_idle_pids(task->pids);
init_idle(task, cpu);
}
return task;
}
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
trace_sched_process_fork(current, p);
nr = task_pid_vnr(p);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event(trace, nr);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event(PTRACE_EVENT_VFORK_DONE, nr);
}
} else {
nr = PTR_ERR(p);
}
return nr;
}
/*
* Create a kernel thread.
*/
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL);
}
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL);
}
#endif
#ifdef __ARCH_WANT_SYS_CLONE
#ifdef CONFIG_CLONE_BACKWARDS
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int, tls_val,
int __user *, child_tidptr)
#elif defined(CONFIG_CLONE_BACKWARDS2)
SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#elif defined(CONFIG_CLONE_BACKWARDS3)
SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp,
int, stack_size,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#else
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
#endif
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
#endif
#ifndef ARCH_MIN_MMSTRUCT_ALIGN
#define ARCH_MIN_MMSTRUCT_ALIGN 0
#endif
static void sighand_ctor(void *data)
{
struct sighand_struct *sighand = data;
spin_lock_init(&sighand->siglock);
init_waitqueue_head(&sighand->signalfd_wqh);
}
void __init proc_caches_init(void)
{
sighand_cachep = kmem_cache_create("sighand_cache",
sizeof(struct sighand_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_DESTROY_BY_RCU|
SLAB_NOTRACK, sighand_ctor);
signal_cachep = kmem_cache_create("signal_cache",
sizeof(struct signal_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
files_cachep = kmem_cache_create("files_cache",
sizeof(struct files_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
fs_cachep = kmem_cache_create("fs_cache",
sizeof(struct fs_struct), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
/*
* FIXME! The "sizeof(struct mm_struct)" currently includes the
* whole struct cpumask for the OFFSTACK case. We could change
* this to *only* allocate as much of it as required by the
* maximum number of CPU's we can ever have. The cpumask_allocation
* is at the end of the structure, exactly for that reason.
*/
mm_cachep = kmem_cache_create("mm_struct",
sizeof(struct mm_struct), ARCH_MIN_MMSTRUCT_ALIGN,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_NOTRACK, NULL);
vm_area_cachep = KMEM_CACHE(vm_area_struct, SLAB_PANIC);
mmap_init();
nsproxy_cache_init();
}
/*
* Check constraints on flags passed to the unshare system call.
*/
static int check_unshare_flags(unsigned long unshare_flags)
{
if (unshare_flags & ~(CLONE_THREAD|CLONE_FS|CLONE_NEWNS|CLONE_SIGHAND|
CLONE_VM|CLONE_FILES|CLONE_SYSVSEM|
CLONE_NEWUTS|CLONE_NEWIPC|CLONE_NEWNET|
CLONE_NEWUSER|CLONE_NEWPID))
return -EINVAL;
/*
* Not implemented, but pretend it works if there is nothing to
* unshare. Note that unsharing CLONE_THREAD or CLONE_SIGHAND
* needs to unshare vm.
*/
if (unshare_flags & (CLONE_THREAD | CLONE_SIGHAND | CLONE_VM)) {
/* FIXME: get_task_mm() increments ->mm_users */
if (atomic_read(¤t->mm->mm_users) > 1)
return -EINVAL;
}
return 0;
}
/*
* Unshare the filesystem structure if it is being shared
*/
static int unshare_fs(unsigned long unshare_flags, struct fs_struct **new_fsp)
{
struct fs_struct *fs = current->fs;
if (!(unshare_flags & CLONE_FS) || !fs)
return 0;
/* don't need lock here; in the worst case we'll do useless copy */
if (fs->users == 1)
return 0;
*new_fsp = copy_fs_struct(fs);
if (!*new_fsp)
return -ENOMEM;
return 0;
}
/*
* Unshare file descriptor table if it is being shared
*/
static int unshare_fd(unsigned long unshare_flags, struct files_struct **new_fdp)
{
struct files_struct *fd = current->files;
int error = 0;
if ((unshare_flags & CLONE_FILES) &&
(fd && atomic_read(&fd->count) > 1)) {
*new_fdp = dup_fd(fd, &error);
if (!*new_fdp)
return error;
}
return 0;
}
/*
* unshare allows a process to 'unshare' part of the process
* context which was originally shared using clone. copy_*
* functions used by do_fork() cannot be used here directly
* because they modify an inactive task_struct that is being
* constructed. Here we are modifying the current, active,
* task_struct.
*/
SYSCALL_DEFINE1(unshare, unsigned long, unshare_flags)
{
struct fs_struct *fs, *new_fs = NULL;
struct files_struct *fd, *new_fd = NULL;
struct cred *new_cred = NULL;
struct nsproxy *new_nsproxy = NULL;
int do_sysvsem = 0;
int err;
/*
* If unsharing a user namespace must also unshare the thread.
*/
if (unshare_flags & CLONE_NEWUSER)
unshare_flags |= CLONE_THREAD | CLONE_FS;
/*
* If unsharing a thread from a thread group, must also unshare vm.
*/
if (unshare_flags & CLONE_THREAD)
unshare_flags |= CLONE_VM;
/*
* If unsharing vm, must also unshare signal handlers.
*/
if (unshare_flags & CLONE_VM)
unshare_flags |= CLONE_SIGHAND;
/*
* If unsharing namespace, must also unshare filesystem information.
*/
if (unshare_flags & CLONE_NEWNS)
unshare_flags |= CLONE_FS;
err = check_unshare_flags(unshare_flags);
if (err)
goto bad_unshare_out;
/*
* CLONE_NEWIPC must also detach from the undolist: after switching
* to a new ipc namespace, the semaphore arrays from the old
* namespace are unreachable.
*/
if (unshare_flags & (CLONE_NEWIPC|CLONE_SYSVSEM))
do_sysvsem = 1;
err = unshare_fs(unshare_flags, &new_fs);
if (err)
goto bad_unshare_out;
err = unshare_fd(unshare_flags, &new_fd);
if (err)
goto bad_unshare_cleanup_fs;
err = unshare_userns(unshare_flags, &new_cred);
if (err)
goto bad_unshare_cleanup_fd;
err = unshare_nsproxy_namespaces(unshare_flags, &new_nsproxy,
new_cred, new_fs);
if (err)
goto bad_unshare_cleanup_cred;
if (new_fs || new_fd || do_sysvsem || new_cred || new_nsproxy) {
if (do_sysvsem) {
/*
* CLONE_SYSVSEM is equivalent to sys_exit().
*/
exit_sem(current);
}
if (new_nsproxy)
switch_task_namespaces(current, new_nsproxy);
task_lock(current);
if (new_fs) {
fs = current->fs;
spin_lock(&fs->lock);
current->fs = new_fs;
if (--fs->users)
new_fs = NULL;
else
new_fs = fs;
spin_unlock(&fs->lock);
}
if (new_fd) {
fd = current->files;
current->files = new_fd;
new_fd = fd;
}
task_unlock(current);
if (new_cred) {
/* Install the new user namespace */
commit_creds(new_cred);
new_cred = NULL;
}
}
bad_unshare_cleanup_cred:
if (new_cred)
put_cred(new_cred);
bad_unshare_cleanup_fd:
if (new_fd)
put_files_struct(new_fd);
bad_unshare_cleanup_fs:
if (new_fs)
free_fs_struct(new_fs);
bad_unshare_out:
return err;
}
/*
* Helper to unshare the files of the current task.
* We don't want to expose copy_files internals to
* the exec layer of the kernel.
*/
int unshare_files(struct files_struct **displaced)
{
struct task_struct *task = current;
struct files_struct *copy = NULL;
int error;
error = unshare_fd(CLONE_FILES, ©);
if (error || !copy) {
*displaced = NULL;
return error;
}
*displaced = task->files;
task_lock(task);
task->files = copy;
task_unlock(task);
return 0;
}
代码第97行首先定义了pr-CPU变量 process_counts,类型为unsigned long,并赋初值为0。nr_processes函数遍历了每一个CPU,然后获取了 process_counts per-CPU变量的值,并将之累加到 total上,最后返回 total。
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论