第15章 ElasticSearch搜索引擎

分类: springboot 专栏: springboot3.0新教材 标签: ElasticSearch
2024-02-23 20:50:55 2579浏览
ElasticSearch简介
Elasticsearch (ES)是一个基于 Lucene 构建的开源、分布式、高扩展、高实时 RESTful 接 口全文搜索引擎,它能很方便的使大量数据具有搜索、分析和探索的能力。数据被存储到 Elasticsearch 集群中时,Elasticsearch 利用分词的特性对数据创建索引(倒排索引)。
solr
官方中文文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
1. 应用场景
大型分布式日志分析系统、大型电商商品搜索系统、网盘搜索引擎等,主要用于大数据 收集。
比如杰凡it的全文检索,分词查询
携程旅行的酒店复杂查询(大量数据,如果用数据库mysql做查询那速度会非常慢,redis等基于内存的这种资源宝贵不能放这么多,而且不适合复杂查询)
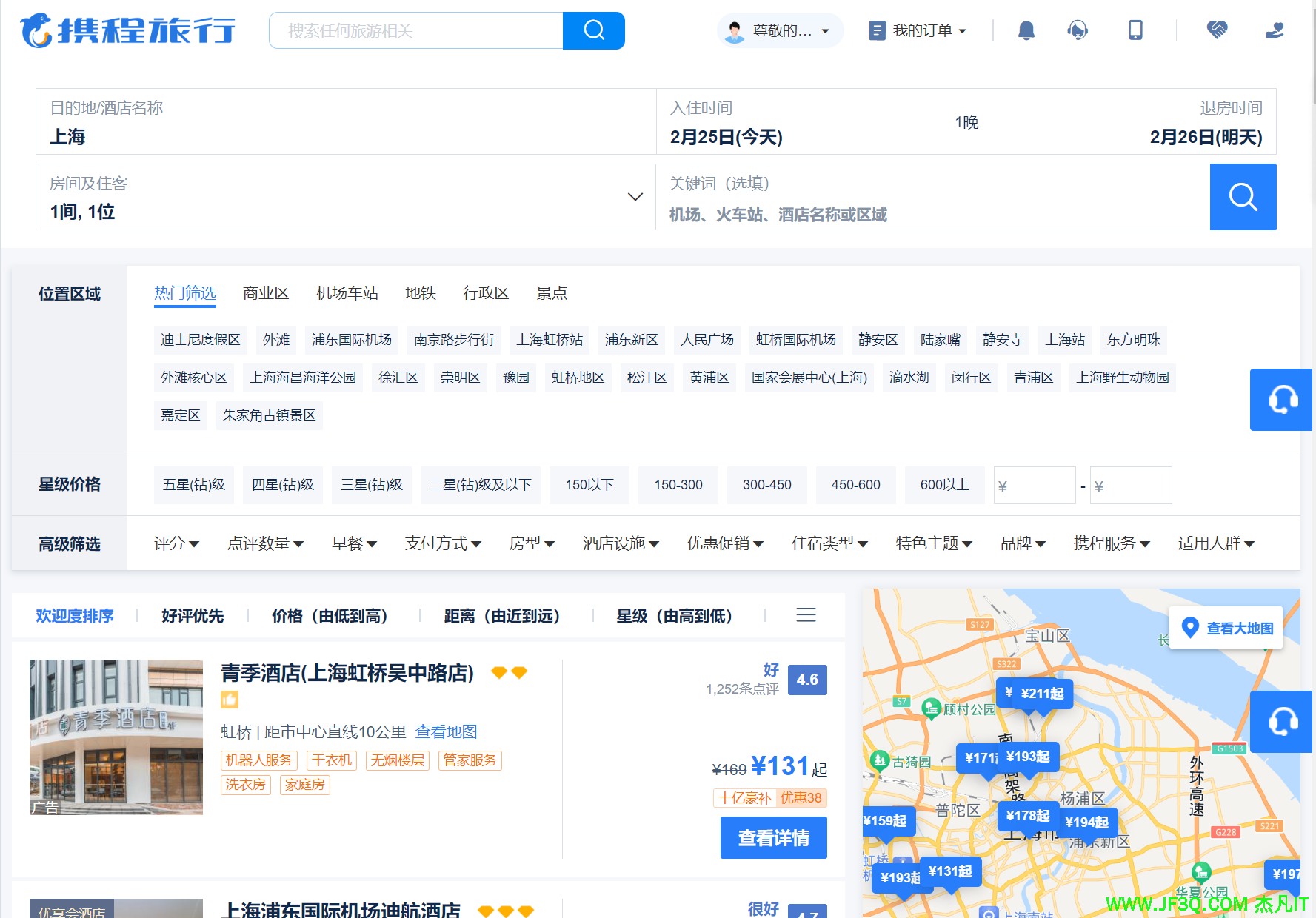
2. 关键概念
1.index(索引):包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分 类索引,订单索引,索引有一个名称。一个 index 包含很多 document,一个 index 就代 表了一类类似的或者相同的 Document。比如说建立一个商品索引,里面可能就存放了 所有的商品数据。 2.type/mapping(类型/映射):它是共享同一索引中一组公共字段的文档集合。例如,索 引包含社交网络应用程序的数据,然后可以有特定类型的用户简档数据、另一种类型的 消息数据和另一种类型的评论数据。 3.Document(文档):它是以 JSON 格式定义的特定方式的字段集合。每个文档都属于一个 类型,并驻留在一个索引中。每个文档都有一个唯一的标识符,称为 UID。
3. 与数据库类比

4. Elasticsearch 存储结构
Elasticsearch 是文件存储,Elasticsearch 是面向文档型数据库,一条数据在这里就是一个 文档,用 JSON 作为文档序列化的格式,比如下面这条数据:
{
"name":"xiaojie",
"sex":"男",
"age":30,
"birthDate":"1994/01/14",
"about":"i love java",
"interests":["music","sports"]
}用 Mysql 这样的数据库存储就会容易想到建立一张 User 表,有 balabala 的字段等,在 Elasticsearch 里这就是一个文档,当然这个文档会属于一个 User 的类型,各种各样的类型存 在于一个索引当中。
ElasticSearch 的下载与安装
首先需要安装 Java 17 才能运行 Elasticsearch,并且要正确配置环境变量 JAVA_HOME。 下载网址:https://www.elastic.co/cn/downloads/
Kibana 是 ElasticSearch 可视化操作工具,也要下载,并且版本要与 ElasticSearch 一致。 下载后解压,进入 ElasticSearch 根目录下的 config 子目录,打开 elasticsearch.yml 文本,修改或添加如下配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:
enabled: false
xpack.security.transport.ssl:
enabled: false以上配置的作用之一是关闭安全设置,否则可能启动不了。
修改 jvm.options 文件,默认为 4G 占用内存,改为 1G:
-Xms1g
-Xmx1g然后进入 bin 目录,双击 elasticsearch.bat 文件即可启动。Kibanba 解压后,打开 bin 目录,双击 kibana.bat 文件启动。两个都正确启动后,浏览器访问 http://localhost:5601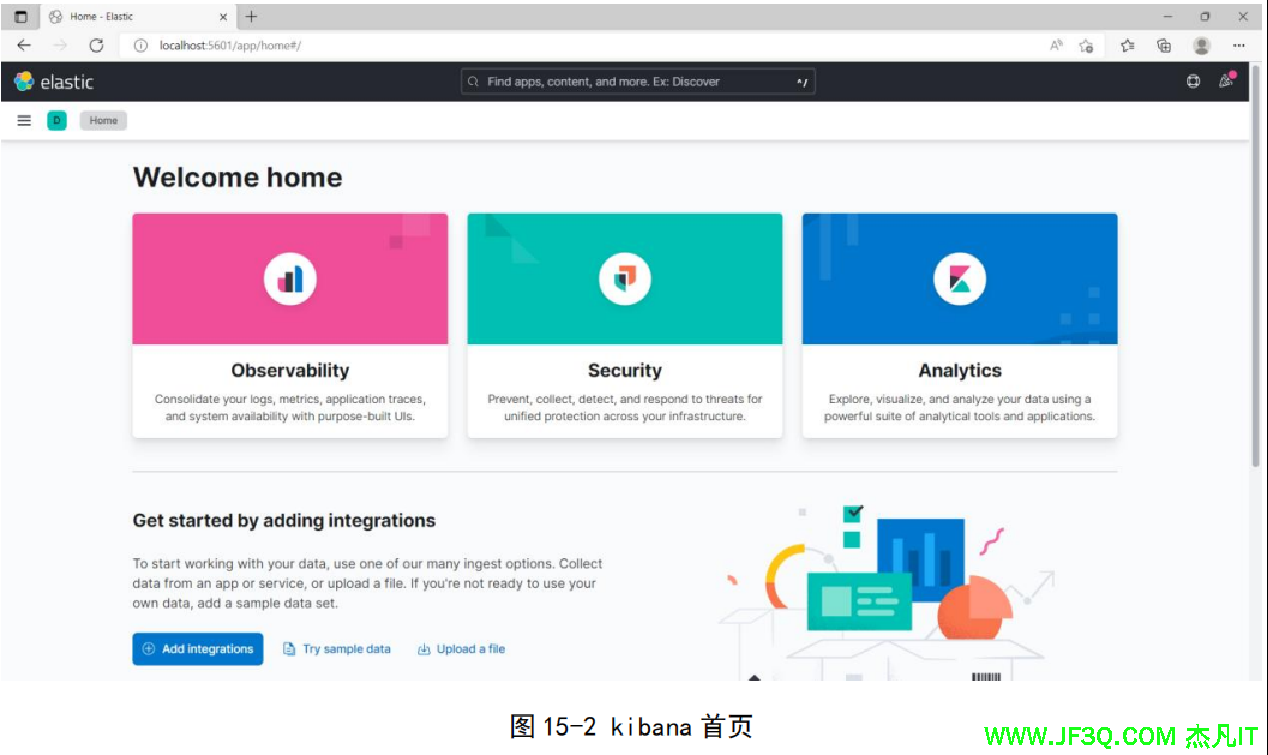
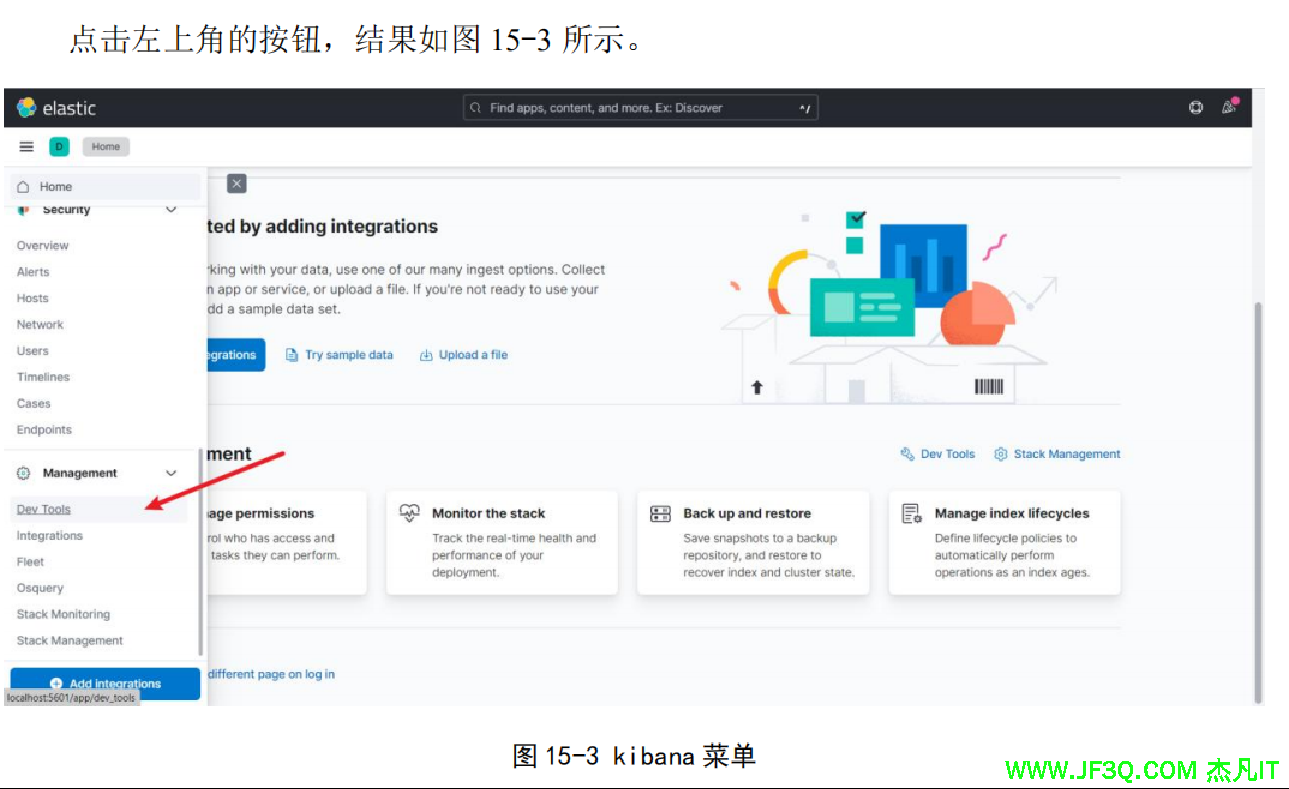
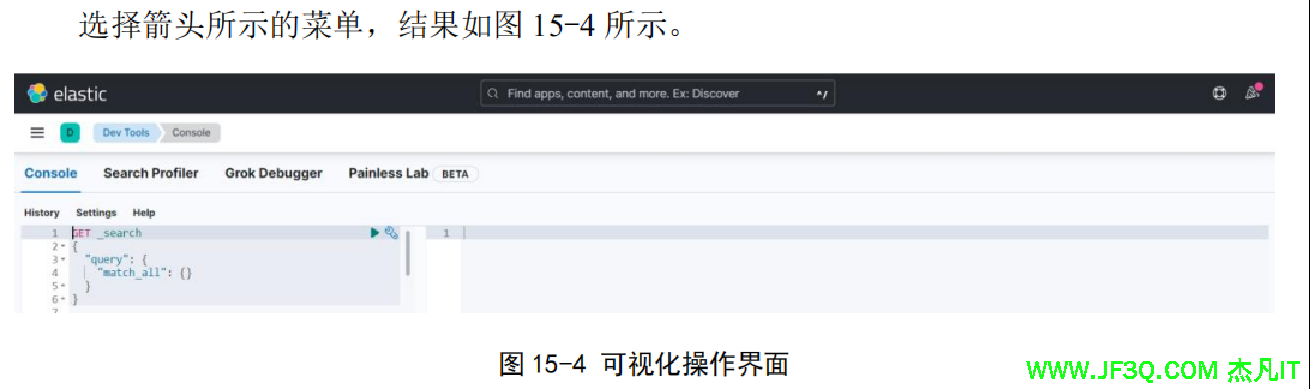
这个就是 ElasticSearch 的可视化操作界面,左侧输入命令,侧显示执行结果。 此外需要另外下载与安装 IK 分词器,这样中文才能正确的进行分词,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases,注意 IK 分词器插件的版本要和 ElasticSearch 的版本一致,下载完后,解压安装包到 ElasticSearch 所在文件夹中的 plugins 目录中,然后重新启动即可。
ElasticSearch 的常用操作
索引操作
- 创建无映射结构的索引
语法:put /索引名称
示例:
PUT /student结果:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "student"
}- 删除索引
语法:delete /索引名称
示例:
DELETE /student结果:
{
"acknowledged": true
}- 创建有映射结构的索引
PUT /student
{
"mappings": {"properties": {
"name":{
"type": "text"
},
"gender":{
"type": "keyword"
},
"age":{
"type": "integer"
},
"city":{
"type": "text"
},
"university":{
"type": "completion"
}
}}
}其中类型为 text 的支持分词,类型为 keyword 的不支持,类型为 completion 的有自动补全效果。
- 查询所有索引
语法:GET /_cat/indices
- 查询指定索引
语法:get /索引名称
文档基本操作
索引建立后就可以向索引添加文档。
- 添加文档不指定文档 id
语法: post /索引名称/_doc {(JSON 格式的数据) }
POST /student/_doc
{
"name":"张三",
"gender":"男",
"age":30,
"city":"北京",
"university":"北京大学"
}结果
{
"_index": "student",
"_id": "uQRTy40B4YBi02Wqhu0c",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}其中_id 后面的值就是系统随机生成的文档编号。
- 添加文档指定文档 id 编号
语法: post /索引名称/_doc/文档 id 编号 {(JSON 格式的数据) }
POST /student/_doc/1
{
"name":"李四",
"gender":"男",
"age":31,
"city":"太原",
"university":"北京理工大学"
}结果
{
"_index": "student",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}显然_id 编号不再是默认的随机编号,而刚刚指定的编号。
为后面查询的需要,下面再添加3个文档
POST /student/_doc/2
{
"name":"李清照",
"gender":"女",
"age":19,
"city":"杭州",
"university":"北京师范大学"
}
POST /student/_doc/3
{
"name":"李白",
"gender":"男",
"age":25,
"city":"杭州",
"university":"清华大学"
}
POST /student/_doc/4
{
"name":"李寻欢",
"gender":"男",
"age":23,
"city":"杭州",
"university":"清华大学"
}- 查询某个索引下的所有文档
语法:get /索引名称/_search
GET /student/_search- 查询指定编号的文档
语法:get /索引名称/_doc/文档 id 编号
GET /student/_doc/1结果如下:
{
"_index": "student",
"_id": "1",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"name": "李四",
"gender": "男",
"age": 31,
"city": "太原",
"university": "北京理工大学"
}
}- 修改指定编号的文档全量修改
语法: put /索引名称/_doc/文档 id 编号 {(完整的 JSON 格式的数据,包含有修改和没修改的所有数据) }
示例:修改李四的年龄为22
PUT /student/_doc/1
{
"name": "李四",
"gender": "男",
"age": 22,
"city": "太原",
"university": "北京理工大学"
}结果:
{
"_index": "student",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1
}观察结果,发现有个updated字样,表示修改成功。
- 修改指定编号的文档局部修改
语法:post /索引名称/_update/文档 id 编号
示例:修改李四的年龄为24
POST /student/_update/1
{
"doc": {
"age":24
}
}- 删除指定编号文档
语法:delete /索引名称/_doc/文档 id 编号。
DELETE /student/_doc/1结果
{
"_index": "student",
"_id": "1",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1
}这样 id 编号为 1 的文档就删除掉了,为了后面方便查找,重新把这个文档添加上去, 即重新执行 post /student/_doc/1 相关语句一次,恢复数据。
文档查询
a. 查询某个索引所有文档
GET /student/_search
{
"query": {
"match_all": {}
}
}b. 条件查询
示例:查询所有男学生信息
GET /student/_search
{
"query": {"match": {
"gender": "男"
}}
}c. 分页查询
示例:查询所有学生信息,显示第1页,每页显示2条
GET /student/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}开始索引是这样算的:(页码-1)*每页显示条数, 上述案例如果要查询第 2 页,则起始 索引应该是 2。
d. 多条件查询
如果多个条件要同时满足,则用关键字 must。
示例:查询年龄为31岁的男生
GET /student/_search
{
"query": {
"bool": {
"must": [
{"match": {
"gender": "男"
}},
{"match": {
"age": 31
}}
]
}
}
}如果多个条件之间是或者关系,则用关键字 should。
示例:查询年龄为23岁的学生或者女生
GET /student/_search
{
"query": {"bool": {"should":
[
{"match": {
"age": 23
}
},
{
"match": {
"gender": "女"
}
}
]}}
}e. 范围查询使用关键字 range
示例:查询年龄在23-25之间的学生
GET /student/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte": 23,
"lte": 25
}
}
}
]
}}
}f. 全文检索与完全匹配
对于类型为 text 的属性,存储数据时系统会进行倒排索引,所以查询出来的数据就会进行全文检索,使用 match 关键字查询时会对所查找的关键词进行分词,然后按分词匹配查找。
示例:查询姓名为李三的学生
GET /student/_search
{
"query": {
"match": {
"name": "李三"
}
}
}结果发现,凡跟李字或三字有关的都查出来了,有张三,有李白,有李清照,有李四,这是因为针对李三进行了分词,分为李、三、李三,系统中存储的每条数据的 name 属性也 同样进行了分词,这样有关的数据就都查出来了。这就是全文检索。
如果要完全匹配查询,则上述关键字 match 要修改为 match_phrase 即可。
示例:查询姓名为李四的学生
GET /student/_search
{
"query": {
"match_phrase": {
"name": "李四"
}
}
}这样就只有一条数据匹配,如果将 match_phrase 改回 match,则除了李白匹配外,其他所有姓李的都能查询出来。 此外 term 查询也是完全匹配,适用于非 text 类型,假设有一个字段的值是”good morning”,则用 term 查询关键字”good”是查询不到的,只有关键字是完整的”good morning”时才能查询到。
g. 模糊查询
示例:查询姓名中包含李字的员工。
GET /student/_search
{
"query": {
"fuzzy": {
"name": "李"
}
}
}此外还可于用 prefix 进行查询,表示前缀,也可用 wildcard 表示使用通配符查询。
GET /student/_search
{
"query": {
"prefix": {
"name": {
"value": "李"
}
}
}
}
GET /student/_search
{
"query": {
"wildcard": {
"name": {
"value": "*四"
}
}
}
}h. 排序
使用关键字 sort 对查询结果进行进行排序
示例:查询李三,并按年龄降序排序
GET /student/_search
{
"query": {
"match": {
"name": "李三"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}i. 高亮显示查询
百度时查询出来的结果中关键字会高亮显示或者颜色特别突出,elasticsearch 也可以实 现这个功能,原理是查询的关键字的前面和后面都添加特殊效果的 HTML 标签,如:<font color=”red”>关键字</font>,这样查询结果中的关键字就会红色显示。
示例:查询姓名为李四的学生,查询结果高亮显示。
GET /student/_search
{
"query": {
"match": {
"name": "李四"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}询结果可以看到关键字都添加了<em></em>包围起来,如果显示到网页上就会有高亮的效果,如果要其他高亮效果比如变红色,则要添加 pre_tags 和 post_tags 属性。
示例:查询李四,关键字红色显示
GET /student/_search
{
"query": {
"match": {
"name": "李四"
}
},
"highlight": {
"fields": {
"name": {}
},
"pre_tags": "<font color='red'>",
"post_tags": "</font>"
}
}j. 聚合查询
使用关键字 aggs。
示例:按姓名查询,查询姓名为李四的学生,并且按照性别进行聚合
GET /student/_search
{
"query": {
"match": {
"name": "李四"
}
},
"aggs": {
"gender_group": {
"terms": {
"field": "gender"
}
}
}
}其中age_group是自定义的聚合名称,部分结果如下:
"aggregations": {
"age_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "男",
"doc_count": 3
},
{
"key": "女",
"doc_count": 1
}
]
}
}可见不同性别的数量都进行了统计
使用 Java API Client 操作 ElasticSearch
依赖
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.2.2</version>
</dependency>配置文件
es.port=9200
es.hostname=localhost
es配置类
@Configuration
public class ElasticSearchConfig {
@Value("${es.hostname}")
private String hostname;
@Value("${es.port}")
private int port;
//注入IOC容器
@Bean
public ElasticsearchClient elasticsearchClient() {
/**
* 通过 RestClient.builder() 方法创建一个 RestClient 实例,
* 并通过 HttpHost 指定 Elasticsearch 服务器的主机名(localhost)、端口号(9200)和协议(http)。
* 这个 RestClient 实例是用来与 Elasticsearch 服务器建立连接的。
*/
RestClient client = RestClient.builder(new HttpHost(hostname, port, "http")).build();
//RestClientTransport 是 Elasticsearch Transport 模块提供的一个实现,用于实现 Elasticsearch 客户端的底层通信。
ElasticsearchTransport transport = new RestClientTransport(client, new JacksonJsonpMapper());
//ElasticsearchClient 是你自定义的 Elasticsearch 客户端类,可能包含了一些封装和业务逻辑
return new ElasticsearchClient(transport);
}
}
实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student {
private String name;
private String gender;
private Integer age;
private String city;
private String university;
}@Data
@AllArgsConstructor
@NoArgsConstructor
public class Emp {
private String empno;
private String ename;
private String gender;
private Integer age;
private String job;
private Integer salary;
private String department;
}测试类
1. 索引操作
@Autowired
ElasticsearchClient client;
@Test
void createIndex() throws IOException { //创建索引
//写法比RestHighLevelClient更加简洁
CreateIndexResponse indexResponse = client.indices().create(c -> c.index("emp"));
System.out.println(indexResponse);
System.out.println(indexResponse.acknowledged());//创建成功true 失败false
}
@Test
void existsIndex() throws IOException { // 判断索引是否存在
BooleanResponse booleanResponse = client.indices().exists(e -> e.index("emp"));
System.out.println(booleanResponse.value());
}
//查看某个索引信息
@Test
void findIndex() throws IOException {
GetIndexResponse getIndexResponse = client.indices().get(getIndex
-> getIndex.index("emp"));
System.out.println(getIndexResponse.result());
}
//查看所有索引信息
@Test
void findIndexes() throws IOException {
IndicesResponse indicesResponse = client.cat().indices();
System.out.println(indicesResponse.valueBody());
}
//删除某个索引
@Test
void deleteIndex() throws IOException {
DeleteIndexResponse deleteIndexResponse = client.indices().delete(d -> d.index("emp"));
System.out.println(deleteIndexResponse.acknowledged());
}
创建索引的时候改成普通写法
CreateIndexRequest request = new CreateIndexRequest.Builder().index("test_emp").build();
CreateIndexResponse indexResponse = client.indices().create(request);
2. 文档基本操作
1.添加文档
@Test //添加文档
void addDocument() throws IOException {
Emp emp = new Emp("1", "李白", "男", 20, "经理", 10000, "销售部");
IndexResponse indexResponse = client.index(i -> i
.index("emp") //索引名称
.id(emp.getEmpno()) //设置id
.document(emp)); //存入emp对象作为文档,会自动转换为JSON格式
System.out.println(indexResponse);
}2.批量添加文档
//批量添加文档
@Test
public void bulkTest() throws IOException {
List<Emp> empList = new ArrayList<>();
empList.add(new Emp("2", "杜甫", "男", 25, "销售", 10000, "销售部"));
empList.add(new Emp("3", "李清照", "女", 20, "经理", 20000, "宣传部"));
empList.add(new Emp("4", "苏东坡", "男", 25, "销售", 20000, "销售部"));
empList.add(new Emp("5", "王维", "男", 20, "策划", 10000, "宣传部"));
List<BulkOperation> bulkOperationArrayList = new ArrayList<>();
//遍历添加到bulk中
for (Emp emp : empList) {
bulkOperationArrayList.add(BulkOperation.of(o -> o.index(i -> i.document(emp).id(emp.getEmpno()))));
}
BulkResponse bulkResponse = client.bulk(b -> b.index("emp")
.operations(bulkOperationArrayList));
System.out.println(bulkResponse);
}换种写法:
//批量添加文档
@Test
void testBatchAddDoc() throws IOException {
List<Emp> empList = new ArrayList<>();
empList.add(new Emp("2", "杜甫", "男", 25, "销售", 10000, "销售部"));
empList.add(new Emp("3", "李清照", "女", 20, "经理", 20000, "宣传部"));
empList.add(new Emp("4", "苏东坡", "男", 25, "销售", 20000, "销售部"));
empList.add(new Emp("5", "王维", "男", 20, "策划", 10000, "宣传部"));
List<BulkOperation> bulkOperationList = new ArrayList<>();
//遍历添加到bulk中
for (Emp emp : empList) {
IndexOperation<Object> indexOperation = new IndexOperation.Builder<>().document(emp).id(emp.getEmpno()).build();
BulkOperation bulkOperation = new BulkOperation.Builder().index(indexOperation).build();
bulkOperationList.add(bulkOperation);
}
BulkResponse bulkResponse = client.bulk(new BulkRequest.Builder().index("test_emp").operations(bulkOperationList).build());
System.out.println(bulkResponse);
}这个代码还隐含一项重要作用就是可以将数据库的数据查出来后转换为 ElasticSearch 存储。
3.查询指定编号的文档
//查询文档
@Test
public void getDocumentTest() throws IOException {
GetResponse<Emp> getResponse = client.get(g -> g
.index("emp")//索引名称
.id("1")//文档id编号
, Emp.class
);
System.out.println(getResponse.source());
}4.判断某个编号的文档是否存在
//判断文档是否存在
@Test
public void existDocumentTest() throws IOException {
BooleanResponse indexResponse = client.exists(e -> e.index("emp").id("1"));
System.out.println(indexResponse.value());
}注意小心跟判断索引是否存在冲突
换种写法
@Test
public void existDocumentTest() throws IOException {
co.elastic.clients.elasticsearch.core.ExistsRequest existsRequest = new co.elastic.clients.elasticsearch.core.ExistsRequest.Builder().index("test_emp").id("1").build();
BooleanResponse exists = client.exists(existsRequest);
System.out.println(exists.value());
}5.更新指定编号的文档
// 更新文档
@Test
public void updateDocumentTest() throws IOException {
//修改后的Emp对象
Emp emp=new Emp("1", "李白", "男", 20, "经理", 20000, "销售部");
UpdateResponse<Emp> updateResponse = client.update(u -> u
.index("emp")
.id("1")
.doc(emp) //此处传入修改后的Emp对象
, Emp.class);
}换种写法
@Test
void testUpdateDoc() throws IOException {
//修改后的Emp对象
Emp emp=new Emp("1", "李白", "男", 20, "经理", 20000, "销售部");
UpdateRequest updateRequest= new UpdateRequest.Builder<>()
.index("test_emp")
.id("1")
.doc(emp).build();
client.update(updateRequest, Emp.class);
}6.删除文档
//删除文档
@Test
public void deleteDocumentTest() throws IOException {
DeleteResponse deleteResponse = client.delete(d -> d
.index("emp")
.id("1")
);
System.out.println(deleteResponse.id());
}3. 文档查询
a. 查询某个索引的全部文档数据
示例:查询索引 emp 的全部文档数据
//查询某个索引的全部数据
@Test
public void searchAll() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryAll = Query.of(q -> q.matchAll(m -> m));
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryAll).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {//获取查询结果
System.out.println(hit.source());
list.add(hit.source());
}
}换种写法
@Test
void testSearchAllData() throws IOException {
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
System.out.println(search);
List<Hit<Emp>> hits = search.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
}b. 查询某个索引的总文档条数
示例:查询索引 emp 的总文档条数
//查询某个索引的总文档条数
@Test
public void searchCount() throws IOException {
CountRequest countRequest = CountRequest.of(s -> s.index("emp"));
CountResponse countResponse = client.count(countRequest);
System.out.println("总文档条数:" + countResponse.count());
}换一种写法
@Test
void testAllDocCount() throws IOException {
CountRequest countRequest= new CountRequest.Builder().index("test_emp").build();
CountResponse countResponse = client.count(countRequest);
System.out.println(countResponse.count());
}c. 条件查询
示例:查询姓名为李白的员工,有分词效果
//条件查询,查询姓名为李白的员工,有分词效果
@Test
public void searchMatch() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryByName = Query.of(q -> q.match(m -> m.field("ename").query("李白")));
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryByName).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {//获取查询结果
System.out.println(hit.source());
list.add(hit.source());
}
}这里用到了 match 查询。
换种写法
//条件查询
@Test
void testSearch() throws IOException {
MatchQuery matchQuery = new MatchQuery.Builder()
.query("李白")
.field("ename")
.build();
Query query = new Query.Builder()
.match(matchQuery)
.build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.query(query)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
d. 完全匹配查询
示例:查询姓名为李白的员工,无分词效果
//完全匹配查询,查询姓名为李白的员工,无分词效果
@Test
public void searchMatchPhrase() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryByName = Query.of(q -> q.matchPhrase(m -> m.field("ename").query("李白")));
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryByName).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
System.out.println(hit.source());
list.add(hit.source());
}
}这里用到了 matchPhrase 查询。
换种写法
//条件查询-完全匹配
@Test
void testSearch() throws IOException {
MatchPhraseQuery matchQuery = new MatchPhraseQuery.Builder()
.query("李清照")
.field("ename")
.build();
Query query = new Query.Builder()
.matchPhrase(matchQuery)
.build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.query(query)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
}e. 多条件查询(and)
示例:查询姓名为李白的男员工
//多条件查询,多个条件都同时要满足(逻辑关系为and),查询姓名为李白的男员工
@Test
public void searchBoolMust() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryByEname = Query.of((q -> q.match(m -> m.field("ename").query("李白"))));
Query queryByGender = Query.of((q -> q.match(m -> m.field("gender").query("男"))));
Query bool = Query.of(q -> q.bool(b -> b.must(queryByEname).must(queryByGender)));
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(bool).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
System.out.println(hit.source());
list.add(hit.source());
}
}换种写法
@Test
void testSearchs() throws IOException {
MatchQuery matchQuery1= new MatchQuery.Builder()
.query("李白")
.field("ename")
.build();
MatchQuery matchQuery2= new MatchQuery.Builder()
.query("男")
.field("gender")
.build();
Query query1 = new Query.Builder()
.match(matchQuery1)
.build();
Query query2 = new Query.Builder()
.match(matchQuery2)
.build();
BoolQuery boolQuery = new BoolQuery.Builder()
.must(query1,query2)
.build();
Query query = new Query.Builder()
.bool(boolQuery)
.build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.query(query)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest,Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
}f. 多条件查询(or)
示例:示例:查询姓名为李白的女员工
//多条件查询,多个条件都满足任意一个均可(逻辑关系为or),查询姓名为李白的女员工
@Test
public void searchBoolShould() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query QueryByEname = Query.of((q -> q.match(m -> m.field("ename").query("李白"))));
Query QueryByGender = Query.of((q -> q.match(m -> m.field("gender").query("女"))));
Query bool = Query.of(q -> q.bool(b -> b.should(QueryByEname).should(QueryByGender)));
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(bool).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
System.out.println(hit.source());
list.add(hit.source());
}
}这里用到了 should。
换种写法
@Test
void testOr() throws IOException {
MatchQuery matchQuery1= new MatchQuery.Builder()
.query("李白")
.field("ename")
.build();
MatchQuery matchQuery2= new MatchQuery.Builder()
.query("女")
.field("gender")
.build();
Query query1= new Query.Builder()
.match(matchQuery1)
.build();
Query query2= new Query.Builder()
.match(matchQuery2)
.build();
BoolQuery boolQuery = new BoolQuery.Builder()
.should(query2,query1)
.build();
Query query= new Query.Builder()
.bool(boolQuery)
.build();
SearchRequest searchRequest= new SearchRequest.Builder()
.index("test_emp")
.query(query)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
}g. 模糊查询
示例:查询姓名为中包含李的员工
@Test
public void searchFuzzy() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryByNameFuzzy = Query.of(q -> q.wildcard(m -> m.field("ename").value("*李*")));//包含李字
// Query queryByNameFuzzy = Query.of(q -> q.prefix(m -> m.field("ename").value("李")));//以李字为前缀(开头)
// Query queryByNameFuzzy = Query.of(q -> q.fuzzy(m -> m.field("ename").value("李")));//包含李字
// Query queryByNameFuzzy = Query.of(q -> q.fuzzy(m -> m.field("ename").value("李").fuzziness("2"))); //这样如果相差不超过两个字符,也算
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryByNameFuzzy).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
System.out.println(hit.source());
list.add(hit.source());
}
}换种写法
@Test
void testHaslI() throws IOException {
FuzzyQuery fuzzyQuery = new FuzzyQuery.Builder()
.field("ename")
.value("李")
.build();
Query query = new Query.Builder()
.fuzzy(fuzzyQuery)
.build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.query(query)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
}h. 按指定字段排序
示例:按年龄降序排序
//按指定字段排序,按年龄降序排序
@Test
public void searchAllSort() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryAll = Query.of(q -> q.matchAll(m -> m));
SortOptions sortByAgeDesc = SortOptions.of(o -> o.field(f -> f.field("age").order(SortOrder.Desc)));//按年龄降序,升序就用Asc
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryAll).sort(sortByAgeDesc).build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
System.out.println(hit.source());
list.add(hit.source());
}
}换种写法
@Test
void testOrder() throws IOException {
/*对所有文档排序,可以不加query,如果是带条件查询并排序的话就加上*/
// Query query = new Query.Builder()
// .build();
FieldSort fieldSort = new FieldSort.Builder()
.field("age")
.order(SortOrder.Desc)
.build();
SortOptions sortOptions = new SortOptions.Builder()
.field(fieldSort)
.build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
// .query(query)
.sort(sortOptions)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
System.out.println(hit.source());
}
}i. 分页查询
示例:查询第 1 页,每页显示 3 条
//分页查询 查询第1页,每页显示3条
@Test
void searchPage() throws IOException {
int pageNum = 1;//页码
int pageSize = 3;//每页显示条数
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryAll = Query.of(q -> q.matchAll(m -> m));
SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryAll)
.from((pageNum - 1) * pageSize)
.size(pageSize)
.build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
System.out.println(hit.source());
list.add(hit.source());
}
}j. 聚合查询
示例:查询男员工的平均年龄
//聚合查询,查询男员工的平均年龄
@Test
void searchAggr() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryByGender = Query.of(q -> q.match(m -> m.field("gender").query("男")));
SearchRequest searchRequest = new SearchRequest.Builder()
.index("emp")
.query(queryByGender)
.aggregations("avg_age", a -> a.avg(t -> t.field("age")))
.build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
System.out.println("男生平均年龄:" + search.aggregations().get("avg_age").avg().value());
}其中,avg 表示平均值,此外 max 表示最大值,min 表示最小值,sum 表示求和。
换种写法
@Test
void testAggs() throws Exception{
AverageAggregation aggregate= new AverageAggregation
.Builder()
.field("age")
.build();
Aggregation aggregation = new Aggregation.Builder()
.avg(aggregate)
.build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.query(new Query.Builder().match(new MatchQuery.Builder().query("男").field("gender").build()).build())
.aggregations("avg_age",aggregation)
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
System.out.println("平均年龄:"+ searchResponse.aggregations().get("avg_age").avg().value());
}
k. 高亮显示
//高亮显示
@Test
void hightLight() throws IOException {
List<Emp> list = new ArrayList<>(); //备用,可以供其他类调用
Query queryByName = Query.of(q -> q.match(m -> m.field("ename").query("李白")));
String[] fields = {"ename"}; //指定哪些字段要高亮
Highlight highlightBuilder = Highlight.of(h -> { //设置高亮字段的效果,前后缀HTML标签
for (String field : fields) {
h.fields(
field
,
h1 -> h1.preTags("<font color='red'>").postTags("</font>"));
}
return h;
}
);
SearchRequest searchRequest = new SearchRequest.Builder()
.index("emp")
.query(queryByName)
.highlight(highlightBuilder) //添加高亮效果
.build();
SearchResponse<Emp> search = client.search(searchRequest, Emp.class);
for (Hit<Emp> hit : search.hits().hits()) {
Emp emp = hit.source();
emp.setEname(hit.highlight().get("ename").get(0));//将原始字段ename替换为高亮显示效果后的字段
System.out.println(emp);
// System.out.println(hit.source()+"---"+hit.highlight());//也可简单展示进行观察
list.add(emp);
}
}换种写法:
@Test
void testHig() throws Exception{
SearchRequest searchRequest = new SearchRequest.Builder()
.index("test_emp")
.query(new Query.Builder().match(new MatchQuery.Builder().field("ename").query("李白").build()).build())
.highlight(new Highlight.Builder()
// .fields("ename", new HighlightField.Builder().preTags("<font color='red'>").postTags("</font>").build())//可以是多个
.fields("ename", new HighlightField.Builder().preTags("<font color='red'>").postTags("</font>").build()).build())
.build();
SearchResponse<Emp> searchResponse = client.search(searchRequest, Emp.class);
List<Hit<Emp>> hits = searchResponse.hits().hits();
for (Hit<Emp> hit : hits) {
Emp emp = hit.source();
emp.setEname(hit.highlight().get("ename").get(0));
System.out.println(emp);
}
}
l. 自动补全查询
补充命令的方式
注意:下面的请求改成get也行
在Elasticsearch中,要执行自动补全请求,可以使用_search端点并在请求体中添加Suggester配置。以下是一个示例的自动补全请求命令:
POST /your_index_name/_search
{
"suggest": {
"autocomplete_suggest": {
"prefix": "user_input",
"completion": {
"field": "suggest_field",
"size": 10
}
}
}
}
在这个请求中:
your_index_name是你的索引名称,你需要将其替换为实际的索引名称。
autocomplete_suggest是自动补全建议(Suggester)的名称,你可以根据需要自定义。
user_input是用户输入的前缀,用于触发自动补全。
suggest_field是存储自动补全数据的字段名。
size指定返回的自动补全结果数量。
发送以上请求到Elasticsearch后,将会返回符合自动补全条件的结果,你可以根据需要对结果进行处理和展示。
请记住,在实际使用时,你需要根据你的数据模型和需求来调整请求中的索引、字段以及其他参数。我写的案例命令
GET /student/_search
{
"suggest": {
"autocomplete_suggest": {
"prefix": "北",
"completion": {
"field": "university",
"size": 2
}
}
}
}//自动补全查询
@Test
void testCompletion() throws IOException {
List<Student> list = new ArrayList<>(); //备用,可以供其他类调用
Suggester suggester = Suggester.of(s -> s.suggesters("university_suggest", p -> p.prefix("北").
completion(c -> c.field("university").size(3).skipDuplicates(true))));
// Query queryByName = Query.of(q -> q.match(m -> m.field("ename").query("李白")));
SearchRequest searchRequest = new SearchRequest.Builder().index("student").suggest(suggester).build();
// SearchRequest searchRequest = new SearchRequest.Builder().index("emp").query(queryByName).build();
SearchResponse<Student> search = client.search(searchRequest, Student.class);
int size = search.suggest().get("university_suggest").get(0).completion().options().size();
for (int i = 0; i < size; i++) {
Student student = search.suggest().get("university_suggest").get(0).completion().options().get(i).source();
list.add(student);
System.out.println(student);
}
}换种写法
@Test
void testSuggest() throws Exception{
FieldSuggester fieldSuggester = new FieldSuggester.Builder().prefix("北").completion(new CompletionSuggester.Builder().field("university").size(2).build()).build();
SearchRequest searchRequest = new SearchRequest.Builder()
.index("student")
.suggest(new Suggester.Builder().suggesters("autocomplete_suggest",fieldSuggester).build())
.build();
SearchResponse<Student> searchResponse = client.search(searchRequest, Student.class);
int size = searchResponse.suggest().get("autocomplete_suggest").get(0).completion().options().size();
for (int i = 0; i < size; i++) {
Student student = searchResponse.suggest().get("autocomplete_suggest").get(0).completion().options().get(i).source();
System.out.println(student);
}
}搜索引擎自动补全查询实战
要求:实现类似百度搜索的自动补全的效果,即输入一两个字,有关的完整词条就会显示出来供选择。这里输入学校名称前面的几个字,所有以这些字开头的学校都会以列表形式出现在搜索框下面。注意:在 ElascticSearch 中自动补全查询要求字段的类型必须是completion。
创建前端页面 auto.html
模拟百度搜索框,发送 ajax 请求到后台,处理回调数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
* {
margin: 0;
padding: 0;
}
#input1 {
width: 400px;
height: 24px;
margin-left: 100px;
}
div {
width: 404px;
height: 300px;
margin-left: 100px;
background: #eeeeee;
}
#content {
display: none;
}
</style>
</head>
<body>
<br/>
<br/>
<form action="" method="post">
<input id="input1" onkeyup="autocompletion(this)" name="keyword" autocomplete="false"> <input type="submit"
value="搜索">
<div id="content"></div>
</form>
<script src="http://ajax.aspnetcdn.com/ajax/jQuery/jquery-2.1.1.min.js"></script>
<script>
var content = document.getElementById('content')
function autocompletion(obj) {
var prefix = obj.value;
$.getJSON("http://localhost:8080/autocomplete?prefix=" + prefix.trim(), {},
function (data) {
$("#content").html("");
for (var i = 0; i < data.length; i++) {
var pTag = document.createElement('p')
pTag.innerText = data[i].university;
content.appendChild(pTag)
}
$("#content").show();
});
}
$("#input1").blur(function () {
$("#content").hide();
});
</script>
</body>
</html>创建控制器 StudentController
@Controller
public class StudentController {
@Autowired
ElasticsearchClient client;
@GetMapping("/auto") //路由到添加新书页面
public String addStudent(){
return "auto";
}
@GetMapping("/autocomplete") //自动补全查询
@ResponseBody
public String autoComplete(String prefix) throws IOException {
List<Student> list = new ArrayList<>();
Suggester suggester = Suggester.of(s -> s.suggesters("university_suggest", p -> p.prefix(prefix).
completion(c -> c.field("university").size(3).skipDuplicates(true))));
//university_suggest是自定义的自动补全查询的名称,university是查询字段,必须是 completion类型。
SearchRequest searchRequest = new SearchRequest.Builder().index("student").suggest(suggester).build();
SearchResponse<Student> search = client.search(searchRequest, Student.class);
int size=search.suggest().get("university_suggest").get(0).completion().options().size();//查询出来的结果条数
for(int i=0;i<size;i++) {//处理查询结果,封装为泛型集合
Student student=search.suggest().get("university_suggest").get(0).completion().options().get(i).source();
list.add(student);
}
ObjectMapper objectMapper=new ObjectMapper();
return objectMapper.writeValueAsString(list);
}
}
测试

搜索引擎高亮显示查询关键字实战
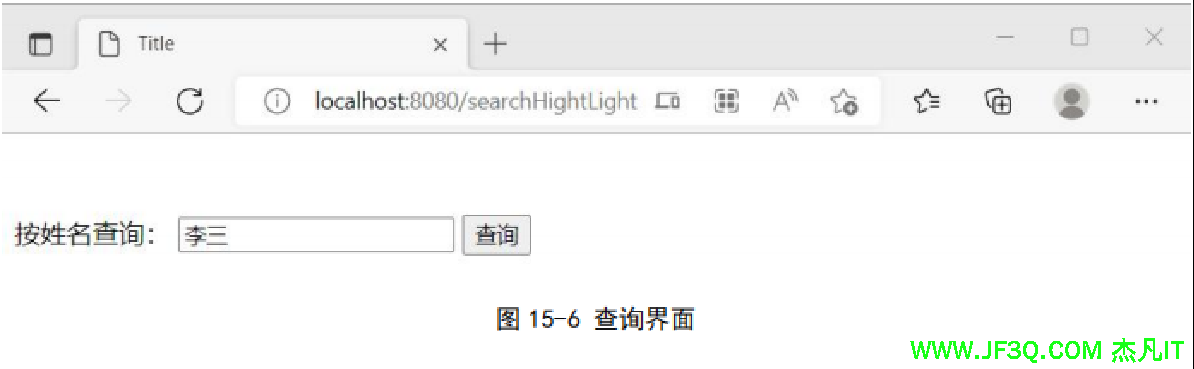
创建前端搜索页面 searchHightLight.html
<form action="/searchHightLight" method="post">
按姓名查询: <input type="text" name="keyword" autocomplete="false"/>
<input type="submit" value="查询"/>
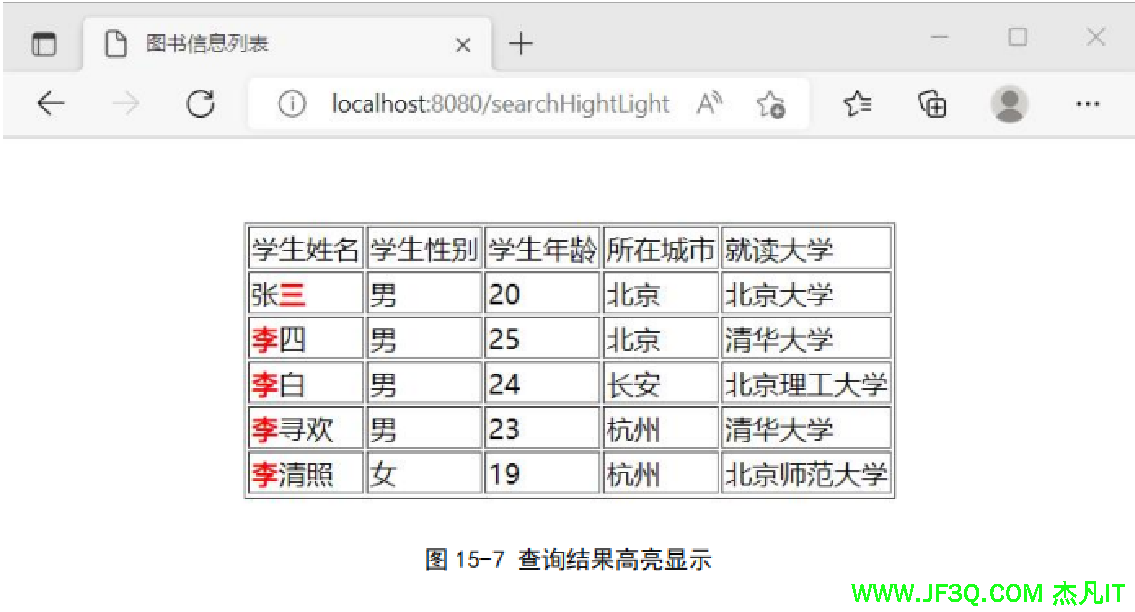
</form>创建前端显示结果页面 students.html
<!--<div>-->
<!-- <form action="/search2" method="post">-->
<!-- 学生姓名:<input type="text" name="name" /><br/>-->
<!-- 学生性别:<input type="text" name="gender" /><br/>-->
<!-- 学生年龄:<input type="text" name="age" /><br/>-->
<!-- 所在城市:<input type="text" name="city" /><br/><br/>-->
<!-- <input type="submit" value="多条件查询"/>-->
<!-- </form>-->
<!--</div>-->
<br/>
<table border="1" align="center">
<tr>
<td>学生姓名</td>
<td>学生性别</td>
<td>学生年龄</td>
<td>所在城市</td>
<td>就读大学</td>
</tr>
<tr th:each="student:${students}">
<td th:utext="${student.name}"></td>
<td th:text="${student.gender}"></td>
<td th:text="${student.age}"></td>
<td th:text="${student.city}"></td>
<td th:text="${student.university}"></td>
</tr>
</table>
</body>
</html>controller
@GetMapping("/searchHightLight") //转到视图
public String searchHightLight(){
return "searchHightLight";
}
@PostMapping("/searchHightLight") //根据关键字查询并高亮显示
public ModelAndView search(String keyword) throws IOException {
System.out.println("keyword:"+keyword);
List<Student> list = new ArrayList<>();
Query queryByName = Query.of(q -> q.match(m -> m.field("name").query(keyword)));
String[] fields = {"name"}; //指定哪些字段要高亮
Highlight highlightBuilder = Highlight.of(h -> { //设置高亮字段的效果,前后缀HTML标签
for (String field : fields) {
h.fields(
field
,
h1 -> h1.preTags("<b><font color='red'>").postTags("</font></b>"));
}
return h;
}
);
SearchRequest searchRequest = new SearchRequest.Builder()
.index("student")
.query(queryByName)
.highlight(highlightBuilder) //添加高亮效果
.build();
SearchResponse<Student> search = client.search(searchRequest, Student.class);
for (Hit<Student> hit : search.hits().hits()) {
Student student=hit.source();
String name=hit.highlight().get("name").get(0);
student.setName(name);//将原始字段name替换为高亮显示效果后的字段
list.add(student);
}
ModelAndView mv=new ModelAndView();
mv.addObject("students",list);
mv.setViewName("students");
return mv;
}
// @PostMapping("/search2") //多条件查询,选做
// public ModelAndView search(Student student) throws IOException {
//
// List<Student> list = new ArrayList<>();
// Query queryByName = Query.of((q -> q.match(m -> m.field("name").query(student.getName()))));
// Query queryByGender = Query.of((q -> q.match(m -> m.field("gender").query(student.getGender()))));
// Query queryByAge = Query.of((q -> q.match(m -> m.field("age").query(student.getAge()))));
// Query queryByCity = Query.of((q -> q.match(m -> m.field("city").query(student.getCity()))));
//
// Query bool = Query.of(q -> q.bool(b -> b
// .must(queryByName)
// .must(queryByGender)
// .must(queryByAge)
// .must(queryByCity)));
// SearchRequest searchRequest = new SearchRequest.Builder().index("student").query(bool).build();
// SearchResponse<Student> search = client.search(searchRequest, Student.class);
// for (Hit<Student> hit : search.hits().hits()) {
// list.add(hit.source());
// }
// ModelAndView mv=new ModelAndView();
// mv.addObject("students",list);
// mv.setViewName("students");
// return mv;
// }
// @GetMapping("/findAllStudents") //查询所有学生信息
// public ModelAndView findAllStudents() throws IOException {
// List<Student> list = new ArrayList<>(); //备用,可以供其他类调用
// Query queryAll = Query.of(q -> q.matchAll(m -> m));
// SearchRequest searchRequest = new SearchRequest.Builder()
// .index("student")
// .query(queryAll)
// .build();
// SearchResponse<Student> search = client.search(searchRequest, Student.class);
// for (Hit<Student> hit : search.hits().hits()) {
// Student student=hit.source();
// list.add(student);
// }
// ModelAndView mv=new ModelAndView();
// mv.addObject("students",list);
// mv.setViewName("students");
// return mv;
// }测试
好博客就要一起分享哦!分享海报
此处可发布评论
评论(1)展开评论
您可能感兴趣的博客
 新业务
新业务  springboot学习
springboot学习  ssm框架课
ssm框架课  vue学习
vue学习  【带小白】java基础速成
【带小白】java基础速成 