redis(2)

标签: redis(2)
2023-05-19 18:23:26 288浏览
一)jedis客户端的使用
jedis:以redis命令作为方法名称,redis一个命令对应着JAVA中的一个方法,学习成本比较低,但是使用jedis实例是线程不安全的,基本每一个线程都要创建一个jedis对象
引入依赖:
<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version> </dependency>为什么使用连接池?
长连接请求方式:建立一次链接可以长期反复使用
短链接请求方式:建立一次链接完成任务后就关闭此链接
mysql、redis、dubbo通常建议都是使用长连接,通过连接池的方式复用连接
互联网高并发场景下, 如果是短连接那需要频繁建立和删除大量的连接,会造成、资源浪费
1)大量的连接握手验证解析的时间=性能问题
2)大量的连接资源申请、分配内存、清理=性能问题
当服务器出现大量请求的时候,回想数据库不断地发出连接请求,多次重复的链接很容易造成数据库服务器宕机,由于数据库资源是很重要的,为了避免因为数据库的原因导致整个程序的影响,所以引入连接池,连接池负责分配刮玻璃和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是新创建一个
长连接想要达到建立一次连接可以长期反复使用的目的,必然需要有一个地方来分配管理连接,不然很多请求过来使用连接的时候就乱套了。因此连接池的作用就出来了,主要体现在以下几方面:
负责分配、管理和释放连接
允许应用程序重复使用一个现有的连接,而再不是重新建立一个
释放空闲时间超过最大空闲时间的连接,减少资源浪费最大连接数:能够同时建立的“最大链接个数,redis服务器可以配置最大允许的客户端连接数
最大空闲数:空闲链接数大于maxIdle时,将进行回收
最小空闲数:低于minIdle时,将创建新的链接
最大等待时间:单位ms
1)最小空闲连接数:在连接池在初始化的时候会创建一定数量的连接放到连接池中,无论这些连接是否被使用,连接池都一直保证至少拥有这么多的连接数量,在系统启动的时候就会被创建,也叫连接池预热,避免系统启动的时候,突然爆发大量请求导致短时间创建大量链接,影响性能,如果说最小空闲连接数创建的过多,那么会导致应用程序对连接数的使用量不大,也会造成系统资源的浪费
2)连接池中允许存在的最大空闲连接数。
比如 minIdle = 10 ;maxIdle = 20 ;maxtotal =40,随着并发量逐渐增加,连接数量逐渐变大,但不会超过40,一段时间后,并发量下降,由于默认取maxIdle配置的连接数量20,所以超出20的连接会被释放,池中稳定存在20个连接,此时的关闭数据库连接,并非真正关闭,而是将其放入空闲队列中。如实际空闲连接数大于初始空闲连接数则释放连接;3)最大连接数是连接池能申请的最大连接数,如果数据连接请求超过此数,后面的数据连接请求将被加入到等待队列中,这会影响之后的数据库操作
3)两者的区别:如果最小连接数与最大连接数相差太大,那么,最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放
因此根据系统应用的实际情况,设置合理的最小空闲连接数、最大空闲连接数、最大连接数,将会一定程度上提升性能。设置连接池的大小肯定不是越大越好,需要考虑的是当前服务所在应用服务器的性能,网络状况,数据库服务器性能,数据库特性等等。你可以设置一个基础值,然后在实际的性能测试过程中,通过微调,来寻找最合适的连接数
spring.redis.database=0 spring.redis.host=124.71.136.248 spring.redis.port=6379 #最大连接数 spring.redis.jedis.pool.max-active=8 #最大空闲数 spring.redis.jedis.pool.max-idle=8 #最小空闲数 spring.redis.jedis.pool.min-idle=1 #最大阻塞时间 spring.redis.jedis.pool.max-wait=-1ms最大阻塞时间:建立连接的最长的等待时间,使用负值无限期等待
进行jedis连接池的配置,注意如果没有密码,那么可以直接可以把传入的密码参数设置为空
package com.example.demo; import lombok.Data; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; import java.time.Duration; @Configuration @ConfigurationProperties(prefix="spring.redis") @Data public class JedisConfig { private int database; private String host; private int port; @Value("${spring.redis.jedis.pool.max-active}") private int MaxActive; @Value("${spring.redis.jedis.pool.max-idle}") private int MaxIdle; @Value("${spring.redis.jedis.pool.min-idle}") private int MinIdle; @Value("${spring.redis.jedis.pool.max-wait}") private String MaxWait; //1.进行jedis连接池配置 public JedisPool GetDataSource(){ //无参构造方法本机IP,需要在配置文件里面获取配置信息 // JedisPool jedisPool=new JedisPool(); //对jedisPool的配置类 System.out.println(host); System.out.println(port); JedisPoolConfig jedisConfig=new JedisPoolConfig(); jedisConfig.setMaxWait(Duration.ofMillis(Long.parseLong(MaxWait))); jedisConfig.setMinIdle(MinIdle); jedisConfig.setMaxIdle(MaxIdle); jedisConfig.setMaxTotal(MaxActive); JedisPool jedisPool=new JedisPool(jedisConfig,host,port,2000,null,0); return jedisPool; } }@Controller public class UserController { @Autowired private JedisConfig jedisConfig; @RequestMapping("/Java100") @ResponseBody public String start(){ JedisPool jedisPool=jedisConfig.GetDataSource(); Jedis jedis=jedisPool.getResource(); jedis.set("name","zhangsan"); return jedis.get("name"); } }
1)用jedis操作String类型:
jedis客户端可以完成对redis的所有命令操作,redis中有哪些命令,jedis中就有哪些方法
1)判断redis中是否存在该key,如果这个key在redis中存在,那么直接查询对应的redis
2)如果key不存在,那么直接进行查询MYSQL数据库,然后再将数据保存在redis中并进行返回
@RequestMapping("/Java200") @ResponseBody public String run(String key){ String username="message"+key; Jedis jedis=jedisConfig.GetDataSource().getResource(); if(!jedis.exists(key)){//在redis中也有exist key来查看redis中是否存在指定key System.out.println("开始查询MYSQL数据库"); String value="今天是2023年"; jedis.set(key,value); return value; }else{ return jedis.get(key); } }
2)使用jedis操作hash类型:
@RequestMapping("/Java300") @ResponseBody public User findUserByID(int userID){ Jedis jedis=jedisConfig.GetDataSource().getResource(); if(jedis.exists(String.valueOf(userID))){ HashMap<String,String> map= (HashMap<String, String>) jedis.hgetAll(String.valueOf(userID)); User user=new User(); user.setUserID(userID); user.setPassword(map.get("password")); user.setUsername(map.get("username")); return user; } else{ System.out.println("查询的是MYSQL数据库"); User user=new User(); user.setUserID(userID); user.setUsername("张三"); user.setPassword("12503487"); HashMap<String,String> map=new HashMap<>(); map.put("username",user.getUsername()); map.put("password",user.getPassword()); jedis.hmset(String.valueOf(userID),map); return user; } }
缓存:缓存是一个高速数据交换的存储器,使用它可以迅速的访问和操作数据
因为单体应用已经不适用于现在的环境了,所以最终变成分布式系统,本地缓存已经不适用了
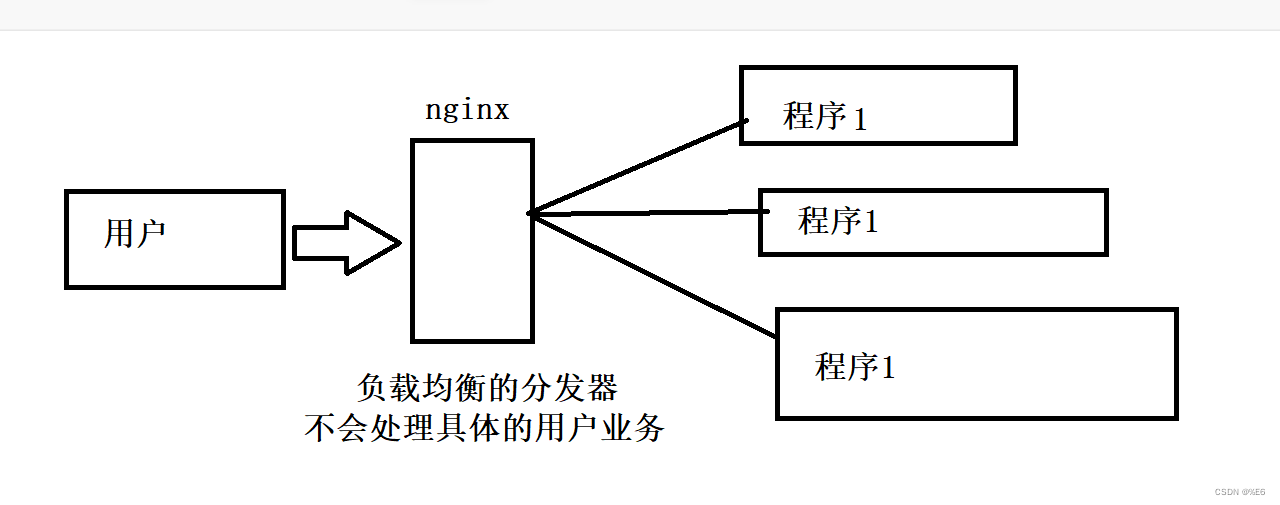
1)比如说张三用户访问了应用程序nginx把请求分配给A服务器
A机器查询数据库,并且把数据库的结果放到缓存中了
2)这时张三再去访问此服务,nginx把这个张三发送过来的请求分配给B服务器了,这时B服务器之前没有过缓存,这时候B服务器还需要再次查询数据库,还需要再把数据库访问的结果放到缓存里面,因为它是本地缓存,他只是对本机缓存有效果,下次张三不去访问这台机器了,那你说缓存还有什么效果呢?因为用户的每一次访问都会被分配到不同的服务器里面
3)缓存的更新问题:假设在分布式服务中有100台机器,张三经过一段时间的时候,这100台服务器都已经保存了本地缓存了,比如说保存了某一次查询的结果,比如说select * from user where userID=1,也就是说本地缓存有100份,100个机器都进行缓存了,假设此时李四把userID=1的用户信息给修改了,李四是在100台服务器上面的某一台机器进行修改的,进行数据的更新,同时也把这一台服务器上面的本地缓存给更新了,但是每一台服务器都有自己的缓存,但是有其他99台服务器的缓存没有进行更新,都是保存在本地的,都是不知道的,其他本地缓存不可知,导致后续访问错误,由此可知本地缓存在分布式场景下已经不适用的,不可感知+不可变更,本地缓存查询和更新都有问题;
4)用户量比较少是可以进行单体应用的,当用户比较多,就必须使用分布式应用了,本地应用是每一台服务器都有着自己本地的缓存,所以我们会把redis部署到一个单独的服务器上面,这台服务器是为所有的应用服务器去服务的;
5)此时所有的应用服务器都是访问同一台redis服务器,这个时候就不会存在说本地缓存中,所有缓存只是保存在一台redis服务器,当服务器访问数据库时,先去查看一下redis服务器里面有没有缓存,如果有直接返回;
6)所以说我们需要将session信息保存在redis缓存中,如果session在每一台机器中缓存,没有分布式缓存,就会意味着一个用户对一个请求,需要登陆多次...
假设小明针对服务进行访问,nginx把请求分发给服务器1,小明进行登录,服务器1保存session信息,但是小明下一次访问服务,nginx把请求分发给服务器2,但是服务器2没有session信息,所以说小明只能重新进行登录,如果有100台服务器,nginx轮询分发服务器,小明难道需要登录100次吗?

使用注解操作redis:
@Cacheable:添加或者查询,判断redis是否有缓存,如果没有缓存就直接把当前方法的返回值存放到redis里面,如果存在就直接返回缓存,并不会将方法进行执行
@CachePut:修改,将方法的返回值添加到redis缓存里面
@CacheEvict:删除,把redis中对应的缓存删除
新增查看缓存
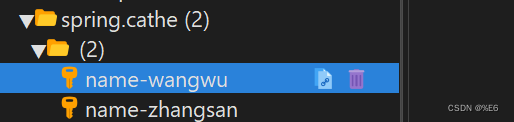
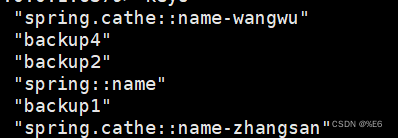
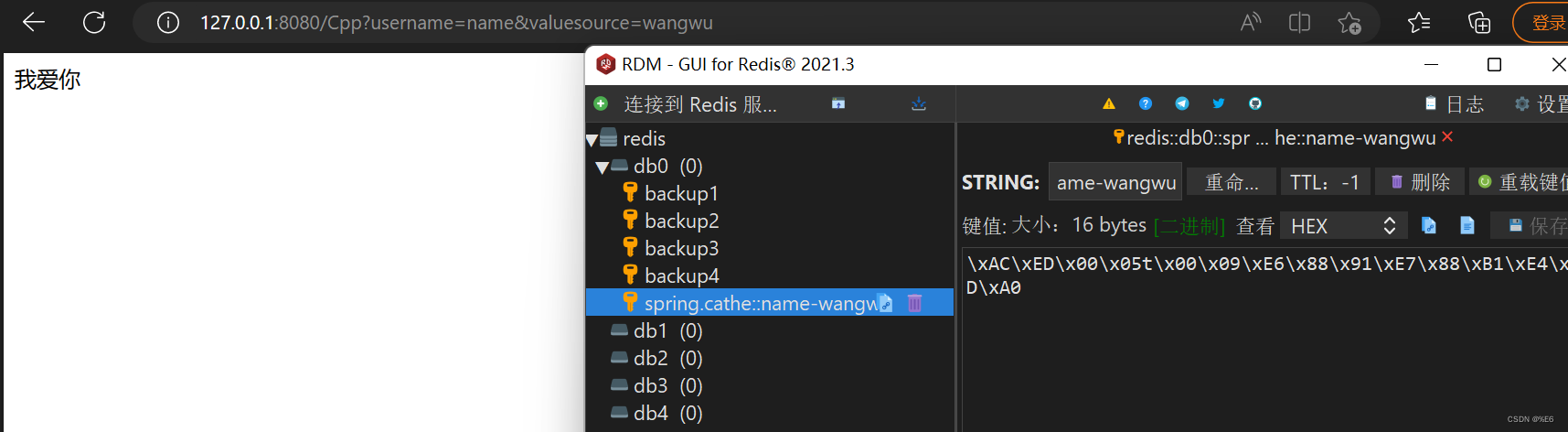
@Controller public class UserController{ @Autowired private StringRedisTemplate redisTemplate; @RequestMapping("/redis") @Cacheable(value="spring.cache",key="#name") @ResponseBody public String start(String name,String value){ //会把传递过来的name值作为保存在redis中的key,会把传递过来的value值作为保存在redis中的value值 (不是把name这个变量名字作为key值) return value; } @RequestMapping("/Java") @Cacheable(value="spring.cathe",key="#username+'-'+#value") @ResponseBody public String run(String username,String value){ System.out.println("执行成功"); return "我爱你"; } @RequestMapping("/Cpp") @Cacheable(value="spring.cathe",key="#username+'-'+#valuesource") @ResponseBody public String get(String username,String valuesource){ System.out.println("执行成功"); return "我爱你"; } }http://127.0.0.1:8080/redis?name=name&value=zhangsan
127.0.0.1:8080/Cpp?username=name&valuesource=wangwu

删除缓存:
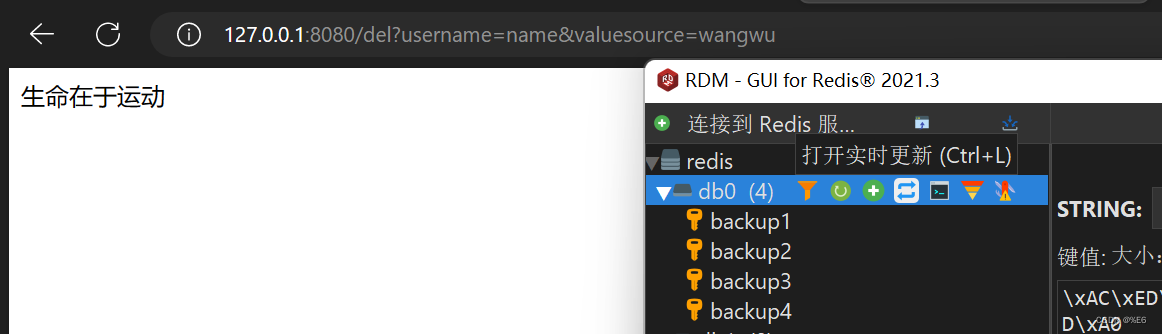
更新缓存:
@RequestMapping("/update") @ResponseBody @CachePut(value="spring.cathe",key="#username+'-'+#valuesource") public String update(String username,String valuesource){ User user=new User(); user.setUserID(1); user.setUsername("李四"); user.setPassword("12503487"); //可以把对象序列化存放到redis里面 return "hello"; }

二)StringRedisTemplate的操作
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对于redis的操作,并且将不同的数据类型的API封装到了不同的类型中
2.1)引入依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency>2.2)编写配置文件:
spring: redis: host: 124.71.136.248 port: 6379 database: 2 # password: #默认为空 lettuce: pool: max-active: 20 #最大连接数,负值表示没有限制,默认8 max-wait: -1 #最大阻塞等待时间,负值表示没限制,默认-1 max-idle: 8 #最大空闲连接,默认8 min-idle: 0 #最小空闲连接,默认0
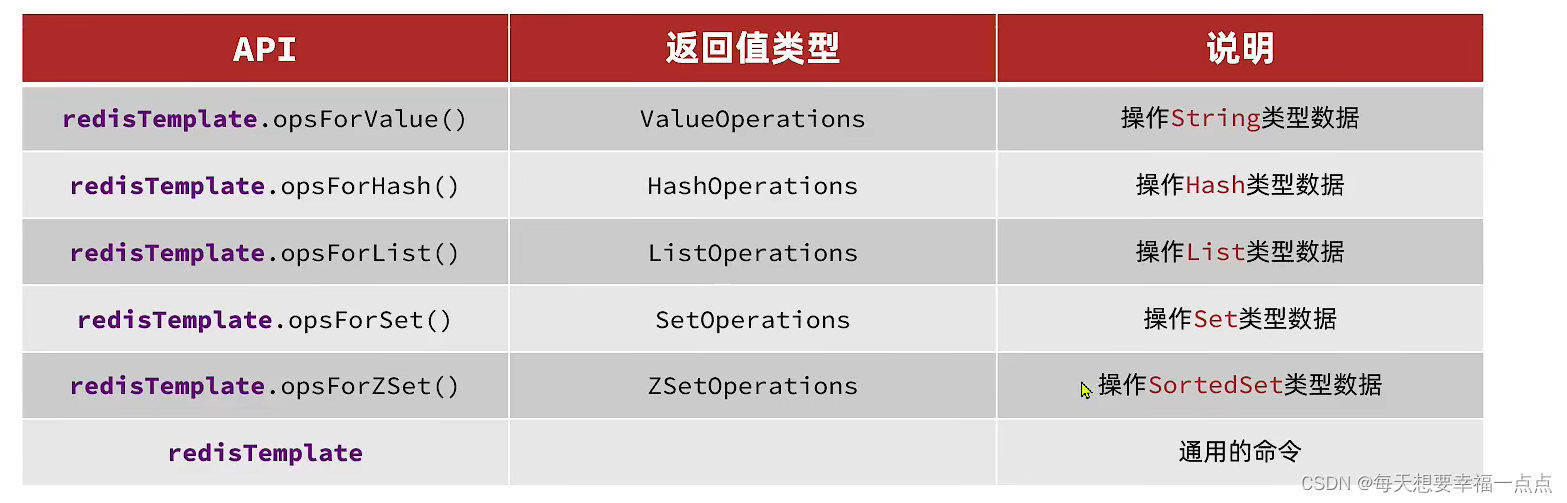
1)redisTemplate.set方法接收到的参数都是Object类型的参数,但是我们实际上传入进去的却是JAVA字符串,redisTemplate可以接受任何参数的对象,然后转成redis可以处理的字节,我们传入set方法的两个字符串都被当成JAVA对象了,而redisTemplate将这两个对象转化成字符串的方式,就是默认使用JDK序列化工具
2)尽管JSON的序列化方式可以满足我们的要求,但是仍然存在一些问题,为了在反序列化的时候知道对象的类型,那么JSON序列化器会将类的class类型写入到JSON结果中,存入到redis里面会带来一定的内存开销
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论